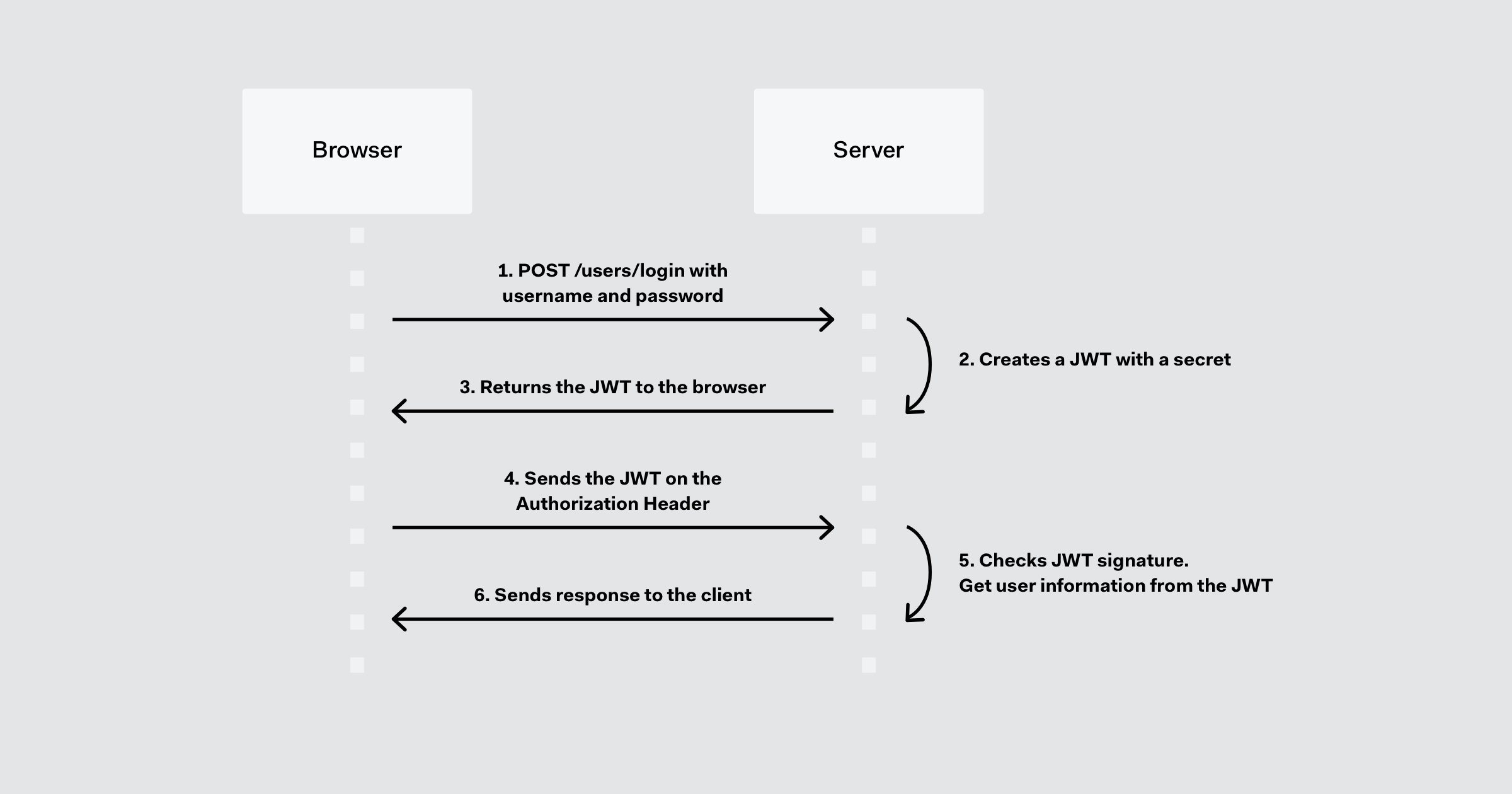
1. What is Node.js? Where can you use it?
Node.js is an open-source, cross-platform JavaScript runtime environment and library to run web applications outside the client’s browser. It is used to create server-side web applications.
Node.js is perfect for data-intensive applications as it uses an asynchronous, event-driven model. You can use I/O intensive web applications like video streaming sites. You can also use it for developing: Real-time web applications, Network applications, General-purpose applications, and Distributed systems.
===========
Node.js is open-source: This means that the source code for Node.js is publicly available. And it's maintained by contributors from all over the world. The Node.js contribution guide shows you how to contribute.
Node.js is cross-platform: Node.js is not dependent on any operating system software. It can work on Linux, macOS, or Windows.
Node.js is a JavaScript runtime environment: When you write JavaScript code in your text editor, that code cannot perform any task unless you execute (or run) it. And to run your code, you need a runtime environment.
==================
Node.js is an open-source server side runtime environment built on Chrome's V8 JavaScript engine. It provides an event driven, non-blocking (asynchronous) I/O and cross-platform runtime environment for building highly scalable server-side applications using JavaScript.
==========
NodeJS Process Model
Process Model Nodejs
NodeJS Process Model
Contrary to the traditional web server model, NodeJS uses an event-driven, non-blocking I/O model that makes it lightweight and efficient. The NodeJS process model can be explained with three architectural features of NodeJS.
Single-threaded event loop
Non-Blocking I/O Model
Event-driven and Asynchronous by default
Single Threaded Event Loop
NodeJS runs on a single-threaded environment which means each user request processes on a single thread only. This makes it use lesser resources and run smoothly using events and emitters.
Events are a crucial paradigm of the NodeJS process. Events are actions that instruct the runtime what and when something needs to be completed. Event Emitters are response object instances that can be subscribed to and acted upon to perform operations. Event Emitters emit events based on certain predefined events accepting a callback. According to MDN web docs, event loops are responsible for executing the code, collecting and processing events, and executing queued sub-tasks.
NodeJS has two types of threads: one Event loop also referred to as the main thread, and the k Workers also referred to as the background thread. When a new user request comes in, it is placed in an event queue. Every request consists of a synchronous and asynchronous part. The synchronous part of the request is handled on the main thread while the asynchronous part is handled in the background via the k Workers/ background threads.
Even though we talk about multiple threads, NodeJS is said to be single-threaded as all the requests are received on a single thread, and execution of the asynchronous processes takes place internally.
Non-Blocking I/O Model
Blocking codes or operations are the ones that need to be completed entirely before moving on to another operation. Non-blocking codes are asynchronous and accept callback functions to operate.
As mentioned, every request has a synchronous and asynchronous part. The main thread of NodeJS does not keep waiting for the background thread to complete the asynchronous I/O operations. The main thread keeps switching between other requests to process their synchronous part while the background thread process the asynchronous part.
Event-Driven and Asynchronous By Default
Once the execution of the background thread is complete, the background thread emits events to notify the main thread. Callback functions are associated with asynchronous processes. If the main thread is not free, the request waits for the main thread to be free and then takes up the callback request for further execution.
To provide concurrency, I/O events and callbacks, and other time-consuming operations are asynchronous by default. Node architecture uses libuv, a C library built specifically for NodeJS for handling most asynchronous I/O operations.
What are the benefits of using Node.js? ☆☆
Asynchronous and Event driven – All APIs of Node.js are asynchronous. This feature means that if a Node receives a request for some Input/Output operation, it will execute that operation in the background and continue with the processing of other requests. Thus it will not wait for the response from the previous requests.
Fast in Code execution – Node.js uses the V8 JavaScript Runtime engine, the one which is used by Google Chrome. Node has a wrapper over the JavaScript engine which makes the runtime engine much faster and hence processing of requests within Node.js also become faster.
Single Threaded but Highly Scalable – Node.js uses a single thread model for event looping. The response from these events may or may not reach the server immediately. However, this does not block other operations. Thus making Node.js highly scalable. Traditional servers create limited threads to handle requests while Node.js creates a single thread that provides service to much larger numbers of such requests.
Node.js library uses JavaScript – This is another important aspect of Node.js from the developer's point of view. The majority of developers are already well-versed in JavaScript. Hence, development in Node.js becomes easier for a developer who knows JavaScript.
There is an Active and vibrant community for the Node.js framework – The active community always keeps the framework updated with the latest trends in the web development.
No Buffering – Node.js applications never buffer any data. They simply output the data in chunks.
What is difference between process and threads in Node.js?
1. Process:
Processes are basically the programs that are dispatched from the ready state and are scheduled in the CPU for execution. PCB (Process Control Block) holds the concept of process. A process can create other processes which are known as Child Processes. The process takes more time to terminate and it is isolated means it does not share the memory with any other process.
The process can have the following states new, ready, running, waiting, terminated, and suspended.
2. Thread:
Thread is the segment of a process which means a process can have multiple threads and these multiple threads are contained within a process. A thread has three states: Running, Ready, and Blocked.
The thread takes less time to terminate as compared to the process but unlike the process, threads do not isolate.
Why is Node.js Single-threaded?
Node.js is single-threaded for async processing. By doing async processing on a single-thread under typical web loads, more performance and scalability can be achieved instead of the typical thread-based implementation.
If Node.js is single-threaded, then how does it handle concurrency?
The Multi-Threaded Request/Response Stateless Model is not followed by the Node JS Platform, and it adheres to the Single-Threaded Event Loop Model. The Node JS Processing paradigm is heavily influenced by the JavaScript Event-based model and the JavaScript callback system. As a result, Node.js can easily manage more concurrent client requests. The event loop is the processing model's beating heart in Node.js.
Why Do You Need Environment Variables?
Environment variables can be used in cases when :
- When you have to store sensitive data of the application and do not expose that data to the public repository. For example, if you want to store API keys, passwords, etc. then such data are stored in the .env file using environment variables, and the .env file is added to the gitignore file so that it is not exposed to the public repository when the code is pushed to GitHub.
- When you want to customize your application variables based on the environment your code is running on like a production environment, development environment, or staging environment.
Create React app support custom variables and you don't have to install any other packages.
- Temporary variables can be added using shell and it is validity is the same as shell session validity.
- using the .env file.
How to Create Environment Variables
Environment variables are supported out of the box with Node and are accessible via the env object (which is a property of the process global object.)
To see this in action, you can create your own environment variable right in the Node REPL by appending a variable to the process.env object directly.
For example, to create an environment variable to store the combination on my luggage I could assign the variable like this: process.env.LUGGAGE_COMBO=“12345”.
(A quick aside: environment variables are, by convention, generally written in all caps.)
While this is a neat experiment, you would not use the Node REPL like this in an app. To create environment variables in your Node app, you will probably want to use a package like DotEnv.
How to Use DotEnv
DotEnv is a lightweight npm package that automatically loads environment variables from a .env file into the process.env object.
To use DotEnv, first install it using the command: npm i dotenv. Then in your app, require and configure the package like this: require('dotenv').config().
Note that some packages such as Create React App already include DotEnv, and cloud providers may have different means of setting environment variables all together. So make sure you check the documentation for any packages or providers you are using before you follow any advice in this article.
How to Create a .env File
Once you have DotEnv installed and configured, make a file called .env at the top level of your file structure. This is where you will create all of your environment variables, written in thr NAME=value format. For example, you could set a port variable to 3000 like this: PORT=3000.
You can declare multiple variables in the .env file. For example, you could set database-related environment variables like this:
DB_HOST=localhost
DB_USER=admin
DB_PASSWORD=passwordWhat is the config method?
The config method allows your application to get or set values in all files that are in the config directory.
How to use the config() method to set values
To set values from files in the config directory, we will use the config() method.
In the config() method, we use dot notation to get the value we want. The first parameter we use is the name of the file without .php, and then we drill down like we are trying to access values from an array until we get the specific value we are looking for. The second parameter we pass to the config() method is the new value.


What Is A Token?
Tokens are pieces of data that carry just enough information to facilitate the process of determining a user's identity or authorizing a user to perform an action. All in all, tokens are artifacts that allow application systems to perform the authorization and authentication process.
New to identity concepts? Read Authentication vs Authorization to get started.
Common identity frameworks and protocols use token-based strategies to secure access to applications and resources. For example, we can use OAuth 2.0 for authorization and OIDC for authentication.
OAuth 2.0 is one of the most popular authorization frameworks out there. It is designed to allow an application to access resources hosted by other servers on behalf of a user. OAuth 2.0 uses Access Tokens and Refresh Tokens.
OpenID Connect (OIDC) is an identity protocol that performs user authentication, user consent, and token issuance. OIDC uses ID Tokens.
Want to get up to speed with OAuth2 and OpenID Connect?
DOWNLOAD THE FREE EBOOK
Let's explore the three token types that we use with OAuth 2.0 and OpenID Connect to fulfill the authentication and authorization processes of our application systems. In the process, we'll see the critical role that refresh tokens play in helping developers build applications that offer convenience without compromising security.
Token Types
What's an ID token?
As the name may suggest, an ID token is an artifact that client applications can use to consume the identity of a user. For example, the ID token can contain information about the name, email, and profile picture of a user. As such, client applications can use the ID token to build a user profile to personalize the user experience.
An authentication server that conforms to the OpenID Connect (OIDC) protocol to implement the authentication process issues its clients an ID token whenever a user logs in. The consumers of ID tokens are mainly client applications such as Single-Page Applications (SPAs) and mobile applications. They are the intended audience.
What's an access token?
When a user logins in, the authorization server issues an access token, which is an artifact that client applications can use to make secure calls to an API server. When a client application needs to access protected resources on a server on behalf of a user, the access token lets the client signal to the server that it has received authorization by the user to perform certain tasks or access certain resources.
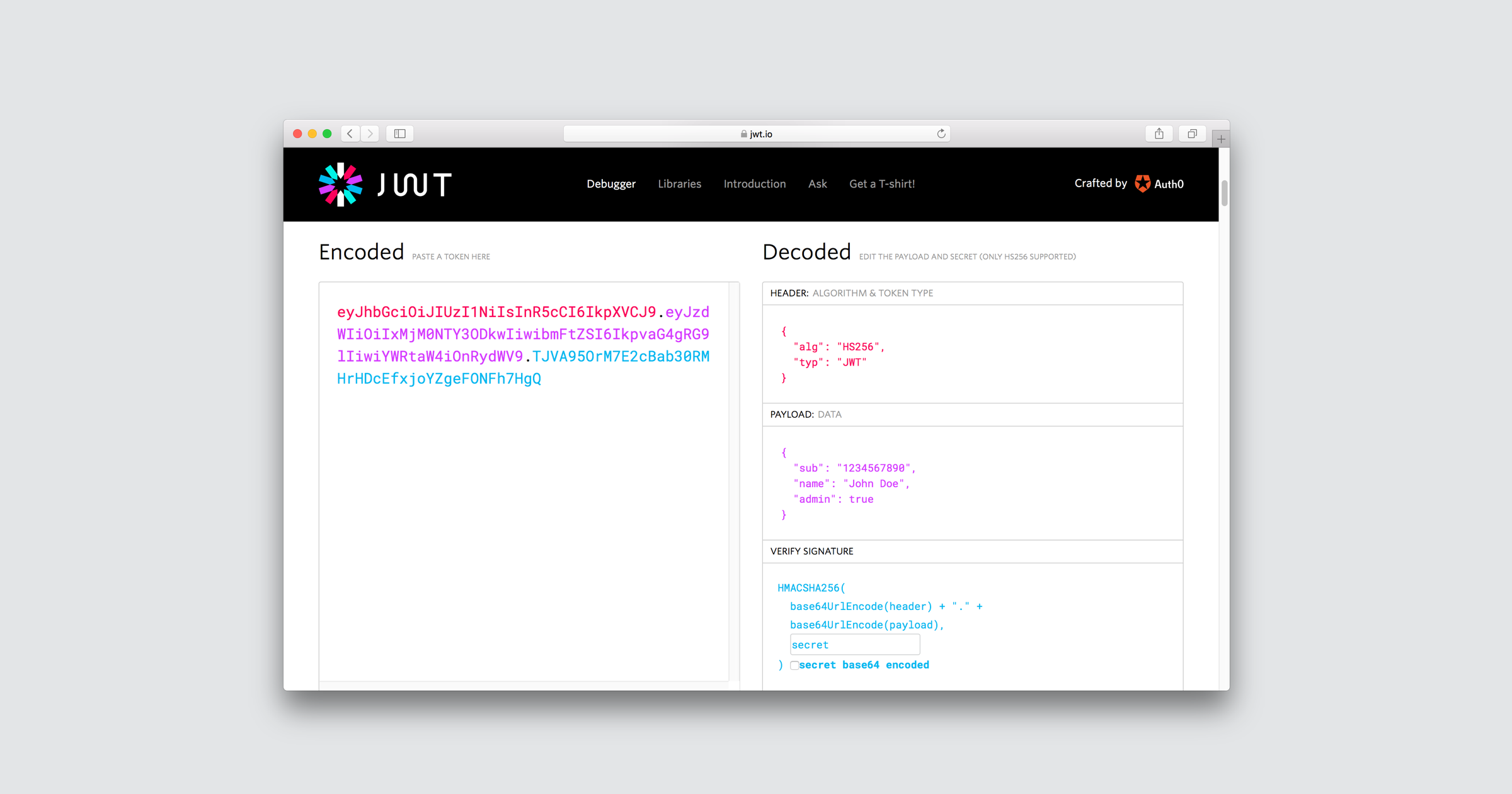
OAuth 2.0 doesn't define a format for access tokens. At Auth0, for example, access tokens issued for the Management API and access tokens issued for any custom API that you have registered with Auth0 follow the JSON Web Token (JWT) standard. Their basic structure conforms to the typical JWT structure, and they contain standard JWT claims asserted about the token itself.
Interested in getting up-to-speed with JWTs as soon as possible?
DOWNLOAD THE FREE EBOOK
This is the content of a decoded access token that follows the JWT format:
{
"iss": "https://YOUR_DOMAIN/",
"sub": "auth0|123456",
"aud": [
"my-api-identifier",
"https://YOUR_DOMAIN/userinfo"
],
"azp": "YOUR_CLIENT_ID",
"exp": 1489179954,
"iat": 1489143954,
"scope": "openid profile email address phone read:appointments"
}It's important to highlight that the access token is a bearer token. Those who hold the token can use it. The access token then acts as a credential artifact to access protected resources rather than an identification artifact. Malicious users could theoretically compromise a system and steal access tokens, which in turn they could use to access protected resources by presenting those tokens directly to the server.
As such, it's critical to have security strategies that minimize the risk of compromising access tokens. One mitigation method is to create access tokens that have a short lifespan: they are only valid for a short time defined in terms of hours or days.
There are different ways that a client application can get a new access token for a user. For example, once an access token expires, the client application could prompt the user to log in again to get a new access token. Alternatively, the authorization server could issue a refresh token to the client application that lets it replace an expired access token with a new one.
You can see both ID tokens and access tokens in action in any of our "Complete Guides to User Authentication" available for React, Angular, Vue, and Node.js!
What Is a Refresh Token?
As mentioned, for security purposes, access tokens may be valid for a short amount of time. Once they expire, client applications can use a refresh token to "refresh" the access token. That is, a refresh token is a credential artifact that lets a client application get new access tokens without having to ask the user to log in again.
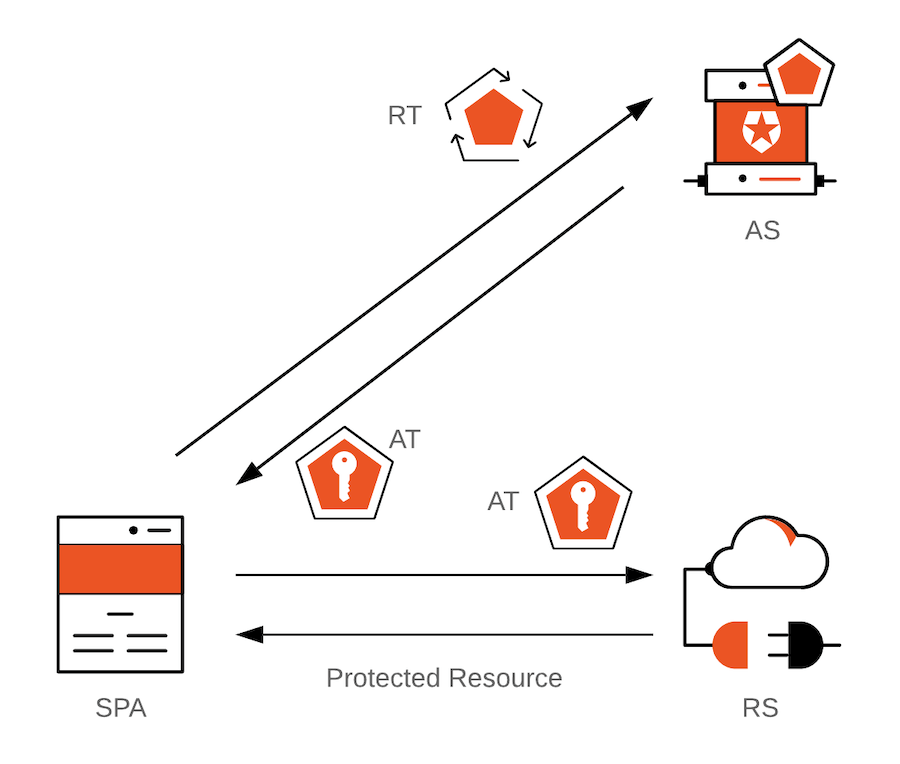
In the diagram above, SPA = Single-Page Application; AS = Authorization Server; RS = Resource Server; AT = Access Token; RT = Refresh Token.
The client application can get a new access token as long as the refresh token is valid and unexpired. Consequently, a refresh token that has a very long lifespan could theoretically give infinite power to the token bearer to get a new access token to access protected resources anytime. The bearer of the refresh token could be a legitimate user or a malicious user. As such, security companies, such as Auth0, create mechanisms to ensure that this powerful token is mainly held and used continuously by the intended parties.
When to Use Refresh Tokens
It's important to keep in mind that the OAuth 2.0 specification defines access tokens and refresh tokens. So, if we were to discuss authorization strategies in terms of other identity protocols or frameworks, such as SAML, we would not have the concepts of access tokens or refresh tokens.
For those involved with web development, access token and refresh tokens are common talk because the web extensively uses token-based authorization and authentication through the OAuth 2.0 framework and the OpenID Connect protocol.
When combined, OAuth 2.0 and OIDC bring to life an array of authorization and authentication flows. Each flow has its own set of benefits and caveats that define the best scenarios and architecture where we should use access and refresh tokens.
Is the client a traditional web application executing on the server? Use the Authorization Code Flow.
Is the client a Single-Page Application (SPA)? Use Authorization Code Flow with Proof Key for Code Exchange (PKCE).
Is the client a Single-Page Application (SPA) that doesn't need an access token? Use the Implicit Flow with Form Post.
Is the client the resource owner? You may use the Client Credentials Flow.
Is the client absolutely trusted with user credentials? You may use the Resource Owner Password Flow.
If there's an app for that, there's also a flow for that!
Keep in mind that according to the spec, when using the Implicit Flow, the authorization server should not issue refresh tokens. The Implicit flow is often implemented in Single-Page Applications (SPAs), which run on the frontend layer of a system architecture. There's no easy way of keeping a refresh token secure in the frontend layer on its own.
Using the Authorization Code Flow with Proof Key for Code Exchange (PKCE) mitigates many risks inherent to the Implicit Flow. For example, when using the implicit grant type, the access token is transmitted in the URI fragment, which can expose it to unauthorized parties. You can learn more about these vulnerabilities by reading the "Misuse of Access Token to Impersonate Resource Owner in Implicit Flow" section of the spec.
However, implementing PKCE in your applications still has no impact on how secure refresh tokens are.
However, you may not need refresh tokens.
There are scenarios where you can still get an access token without interrupting the user and without relying on the almighty power of the refresh token. Other examples to keep a session going can be cookies or silent authentication.
However, billions of people use SPAs every day. It is important to provide users with a user experience that balances security and convenience well. Is there anything that we could do to let SPAs afford the convenience of refresh tokens in a less risky and more secure manner?
Absolutely!
An identity platform that offers Refresh Token Rotation makes it acceptable to use refresh tokens with Single-Page Applications. The spec underlines that when you can not verify that a refresh token belongs to a client, such a SPA, we should not use them unless we have Refresh Token Rotation in place.
Let's learn more about this security strategy in the next section.
Keeping Refresh Tokens Secure
A short-lived access token helps improve the security of our applications, but it comes with a cost: when it expires, the user needs to log in again to get a new one. Frequent re-authentication can diminish the perceived user experience of your application. Even if you are doing so to protect their data, users may find your service frustrating or difficult to use.
A refresh token can help you balance security with usability. Since refresh tokens are typically longer-lived, you can use them to request new access tokens after the shorter-lived access tokens expire.
However, since refresh tokens are also bearer tokens, we need to have a strategy in place that limits or curtails their usage if they ever get leaked or become compromised. All those who hold the refresh tokens have the power to get new access tokens whenever they want. "They" could be legitimate users or attackers.
At Auth0, we created a set of features that mitigate the risks associated with using refresh tokens by imposing safeguards and controls on their lifecycle. Our identity platform offers refresh token rotation, which also comes with automatic reuse detection.
Let's dive deeper into this security technique.
Refresh Token Rotation
Until very recently, a robust strategy to help SPAs maintain the user's session was using the Authorization Code Flow with PKCE in conjunction with silent authentication. Refresh token rotation is a technique for getting new access tokens using refresh tokens that goes beyond silent authentication.
Refresh token rotation guarantees that every time an application exchanges a refresh token to get a new access token, a new refresh token is also returned. Therefore, you no longer have a long-lived refresh token that could provide illegitimate access to resources if it ever becomes compromised. The threat of illegitimate access is reduced as refresh tokens are continually exchanged and invalidated.
For example, with refresh token rotation enabled in the Auth0 Dashboard, every time your application exchanges a refresh token to get a new access token, the authorization server also returns a new refresh-access token pair. This safeguard helps your app mitigate replay attacks resulting from compromised tokens.
Refresh Token Automatic Reuse Detection
Refresh tokens are bearer tokens. It's impossible for the authorization server to know who is legitimate or malicious when receiving a new access token request. We could then treat all users as potentially malicious.
How could we handle a situation where there is a race condition between a legitimate user and a malicious one? For example:
🐱 Legitimate User has 🔄 Refresh Token 1 and 🔑 Access Token 1.
😈 Malicious User manages to steal 🔄 Refresh Token 1 from 🐱 Legitimate User.
🐱 Legitimate User uses 🔄 Refresh Token 1 to get a new refresh-access token pair.
The 🚓 Auth0 Authorization Server returns 🔄 Refresh Token 2 and 🔑 Access Token 2 to 🐱 Legitimate User.
😈 Malicious User then attempts to use 🔄 Refresh Token 1 to get a new access token. Pure evil!
What do you think should happen next? Would 😈 Malicious User manage to get a new access token?
This is what happens when your identity platform has 🤖 Automatic Reuse Detection:
The 🚓 Auth0 Authorization Server has been keeping track of all the refresh tokens descending from the original refresh token. That is, it has created a "token family".
The 🚓 Auth0 Authorization Server recognizes that someone is reusing 🔄 Refresh Token 1 and immediately invalidates the refresh token family, including 🔄 Refresh Token 2.
The 🚓 Auth0 Authorization Server returns an Access Denied response to 😈 Malicious User.
🔑 Access Token 2 expires, and 🐱 Legitimate User attempts to use 🔄 Refresh Token 2 to request a new refresh-access token pair.
The 🚓 Auth0 Authorization Server returns an Access Denied response to 🐱 Legitimate User.
The 🚓 Auth0 Authorization Server requires re-authentication to get new access and refresh tokens.
It's critical for the most recently-issued refresh token to get immediately invalidated when a previously-used refresh token is sent to the authorization server. This prevents any refresh tokens in the same token family from being used to get new access tokens.
This protection mechanism works regardless of whether the legitimate or malicious user is able to exchange 🔄 Refresh Token 1 for a new refresh-access token pair before the other. Without enforcing sender-constraint, the authorization server can't know which actor is legitimate or malicious in the event of a replay attack.
Automatic reuse detection is a key component of a refresh token rotation strategy. The server has already invalidated the refresh token that has already been used. However, since the authorization server has no way of knowing if the legitimate user is holding the most current refresh token, it invalidates the whole token family just to be safe.
Refresh Tokens Help Us Embrace Privacy Tools
Privacy is a hot topic in our digital world. We not only need to balance security with convenience, but we also need to add privacy to the balancing act.
Recent developments in browser privacy technology, such as Intelligent Tracking Prevention (ITP), prevent access to the session cookie, requiring users to reauthenticate.
There is no persistent storage mechanism in a browser that can assure access by the intended application only. As such, long-lived refresh tokens are not suitable for SPAs as there are vulnerabilities that malicious users could exploit to obtain these high-value artifacts, granting them access to protected resources.
Because refresh token rotation does not rely on access to the Auth0 session cookie, it is not affected by ITP or similar mechanisms.
However, a refresh token could have its lifespan limited by the lifespan of an access token. This means we can safely use refresh tokens to play along with browser privacy tools and provide continuous access to end-users without disrupting the user experience.
You Can Store Refresh Token In Local Storage
Yes, you read that right. When we have refresh token rotation in place, we can store tokens in local storage or browser memory.
You may have heard before (maybe from us) that we should not store tokens in local storage.
Storing tokens in browser local storage provides persistence across page refreshes and browser tabs; however, if malicious users managed to run JavaScript in the SPA using a cross-site scripting (XSS) attack, they could retrieve the tokens stored in local storage. A vulnerability leading to a successful XSS attack could be present in the SPA source code or any third-party JavaScript code the app consumes, such as Bootstrap or Google Analytics.
However, we can reduce the absolute token expiration time of tokens to reduce the security risks of storing tokens in local storage. This reduces the impact of a reflected XSS attack (but not of a persistent one). A refresh token may have a long lifespan by configuration. However, the defined long lifespan of a refresh token is cut short with refresh token rotation. The refresh is only valid within the lifespan of the access token, which would be short-lived.
A string is a data structure that represents a sequence of characters, and an array is a data structure that contains multiple values.
And did you know – a string can be broken apart into an array of multiple strings using the split method. Let's see how that works with some examples.
TL;DR
If you just want the code, here you go:
const publisher = 'free code camp'
publisher.split(' ') // [ 'free', 'code', 'camp' ]
Syntax
According to the MDN, the syntax you'll need to split the string is str.split([separator[, limit]]). If we apply this to the above example:
strispublisherseparatoris' '- there is no
limit
When do you need to split a string?
Example 1: getting part of a string
Here is a common example which involves getting the token from an auth header that is part of a Token-based Authentication System.
If this doesn't mean anything to you that's ok. All you need to know for the following example is that there is a string with the value bearer token, but only token is needed (as this is the part that identifies the user):
const authHeader = 'bearer token'
const split = authHeader.split(' ') // (1) [ 'bearer', 'token' ]
const token = split[1] // (2) tokenHere's what's happening in the above code:
- The string is split with
' 'as the separator - The second entry in the array is accessed
Example 2: apply array methods to a string
Often the input you are given is a string, but you want to apply array methods to it (eg. map, filter, or reduce).
For example, let's say you are given a string of morse code and you want to see what it reads in English:
const morse = '-.-. --- -.. .'
// (1)
const morseToChar = {
'-.-.': 'c',
'-..': 'd',
'.': 'e',
'---': 'o',
}
const morseArray = morse.split(' ') // (2) [ '-.-.', '---', '-..', '.' ]
const textArray = morseArray.map((char) => morseToChar[char]) // (3) [ 'c', 'o', 'd', 'e' ]
const text = textArray.join(") // (4)
Here's what's happening in the above code:
- An object literal is created to map morse chars to the English alphabet
- The morse code is split into an array with a
' 'as the separator. (Without' 'as an argument you would end up with an array that has separate entries for each.and-.) - The morse code array is mapped/transformed to a text array
- A string is created from the array with
''as the separator. (Without''as an argument the output would bec,o,d,e.)
How to add a limit to split
According to the MDN, it is also possible to pass a limit as an argument to split. I have never needed to do this, but here is how you could apply it:
const publisher = 'free code camp'
publisher.split(' ', 1) // [ 'free' ]
In the above example, the array is limited to one entry. Without it the value of the array would be [ 'free', 'code', 'camp' ].
Before you go…
Thank you for reading this far! I write about my professional and educational experiences as a self-taught software developer, so feel free to check out my website or subscribe to my newsletter for more content.
while ((line = reader.readLine()) != null)
double crtValue = Double.valueOf(line.split(",")[1]);line#split returns an array, [1] acceses the second element of the returned array.
It means that your line is a String of numbers separated by commas.
eg: "12.34,45.0,67.1"
The line.split(",") returns an array of Strings.
eg: {"12.34","45.0","67.1"}
line.split(",")[1] returns the 2nd(because indexes begin at 0) item of the array.
The Split Token
The split token pattern is in many ways similar to the previously described phantom token. At least the result is the same — the OAuth client deals with an opaque token, and the API's services handle JWTs. In this pattern, though, the API gateway doesn't have to call the introspection endpoint to get a JWT. When the authorization server issues the JWT, it splits it into two parts: one consists of the header and payload of the JWT, and the other is the token's signature. The signature part is returned to the client and used as the opaque token. The header and payload are sent to the API gateway where they are cached, with the signature's hash used as the cache key.
When the client calls the API, it sends the signature part of the token. The API gateway hashes it, looks up the corresponding header and payload in the cache, and, if found, glues the pieces back together to form a JWT. The JWT is thus reconstructed without the need to contact the authorization server.
Comments
Post a Comment