
https://medium.com/life-at-apollo-division/javascript-event-loop-44578bfe2ae2




What is Node.js? Where can you use it?
Node.js is an open-source server side runtime environment built on Chrome's V8 JavaScript engine. It provides an event driven, non-blocking (asynchronous) I/O and cross-platform runtime environment for building highly scalable server-side applications using JavaScript.
What are the benefits of using Node.js? ☆☆
Asynchronous and Event driven – All APIs of Node.js are asynchronous. This feature means that if a Node receives a request for some Input/Output operation, it will execute that operation in the background and continue with the processing of other requests. Thus it will not wait for the response from the previous requests.
Fast in Code execution – Node.js uses the V8 JavaScript Runtime engine, the one which is used by Google Chrome. Node has a wrapper over the JavaScript engine which makes the runtime engine much faster and hence processing of requests within Node.js also become faster.
Single Threaded but Highly Scalable – Node.js uses a single thread model for event looping. The response from these events may or may not reach the server immediately. However, this does not block other operations. Thus making Node.js highly scalable. Traditional servers create limited threads to handle requests while Node.js creates a single thread that provides service to much larger numbers of such requests.
Node.js library uses JavaScript – This is another important aspect of Node.js from the developer's point of view. The majority of developers are already well-versed in JavaScript. Hence, development in Node.js becomes easier for a developer who knows JavaScript.
There is an Active and vibrant community for the Node.js framework – The active community always keeps the framework updated with the latest trends in the web development.
No Buffering – Node.js applications never buffer any data. They simply output the data in chunks.
Why is Node.js Single-threaded?
Node.js is known to be a single-threaded runtime environment, meaning that a program’s code is executed line after line and there can’t be two lines of a program running at the same time.
Node.js is single-threaded for async processing. By doing async processing on a single-thread under typical web loads, more performance and scalability can be achieved instead of the typical thread-based implementation.
event loop runs one process at a time. That means it can only execute one function at a time, and since functions can have multiple instructions, the event loop will execute one instruction at a time
How Nodejs works single single-threaded?
Node.js is a single-threaded runtime environment, which means that it uses a single thread to handle all incoming requests. This may seem counterintuitive, as many other web servers use multiple threads to handle requests in parallel. However, there are several reasons why Node.js uses a single thread for request handling:
- Node.js is built on top of the JavaScript language, which is single-threaded by design. This means that it is easier to use a single thread in Node.js, as it is more consistent with the underlying language.
- Single-threaded architectures are often more scalable than multi-threaded ones. This is because they can better utilize the available CPU resources, and they are less susceptible to thread synchronization issues.
- Node.js uses an event-driven, non-blocking I/O model, which is well-suited to a single-threaded architecture. In this model, long-running operations are handled asynchronously, allowing the thread to continue processing other requests while the operation is in progress.
Here are a few examples of how the single-threaded nature of Node.js can be beneficial:
- Suppose you are building a web application that receives a high volume of requests. With a single-threaded architecture, you can process each request sequentially, without having to worry about thread synchronization or other complex issues.
- Suppose you are building a real-time chat application that needs to handle a large number of concurrent connections. With a single-threaded architecture, you can use the event loop to handle incoming messages and broadcast them to all connected clients, without worrying about thread safety.
- Suppose you are building an API that makes calls to a remote server. With a single-threaded architecture, you can use the event loop to make the calls asynchronously, allowing the thread to continue processing other requests while the remote server is being queried.
Overall, the single-threaded architecture of Node.js can be very beneficial in many different scenarios, as it allows for efficient and scalable request handling.
If Node.js is single-threaded, then how does it handle concurrency?
The Multi-Threaded Request/Response Stateless Model is not followed by the Node JS Platform, and it adheres to the Single-Threaded Event Loop Model. The Node JS Processing paradigm is heavily influenced by the JavaScript Event-based model and the JavaScript callback system. As a result, Node.js can easily manage more concurrent client requests. The event loop is the processing model's beating heart in Node.js.
What is a Module in JavaScript?
In simple terms, a module is a piece of reusable JavaScript code. It could be a .js file or a directory containing .js files. You can export the content of these files and use them in other files.
What is NPM?
NPM (Node Package Manager) is a package manager for Node.js that allows developers to easily install, manage, and share packages of code.
NPM consists of two main parts:
- a CLI (command-line interface) tool for publishing and downloading packages, and
- an online repository that hosts JavaScript packages
What is package.json?
Every npm package and Node.js project has a package.json file with metadata for a project. The file resides in the root directory of every Node.js package and appears after running the npm init command.
The package.json file contains descriptive and functional metadata about a project, such as a name, version, and dependencies. The file provides the npm package manager with various information to help identify the project and handle dependencies.
What is difference between process and threads in Node.js?
1. Process:
Processes are basically the programs that are dispatched from the ready state and are scheduled in the CPU for execution. PCB (Process Control Block) holds the concept of process. A process can create other processes which are known as Child Processes. The process takes more time to terminate and it is isolated means it does not share the memory with any other process.
The process can have the following states new, ready, running, waiting, terminated, and suspended.
2. Thread:
Thread is the segment of a process which means a process can have multiple threads and these multiple threads are contained within a process. A thread has three states: Running, Ready, and Blocked.
The thread takes less time to terminate as compared to the process but unlike the process, threads do not isolate.
Explain the concept of URL module in Node.js?
The URL module splits up a web address into readable parts.
To include the URL module, use the require() method:

var adr = 'http://localhost:8080/default.htm?year=2017&month=february';
var q = url.parse(adr, true);
console.log(q.host); //returns 'localhost:8080'
console.log(q.pathname); //returns '/default.htm'
console.log(q.search); //returns '?year=2017&month=february'
var qdata = q.query; //returns an object: { year: 2017, month: 'february' }
console.log(qdata.month); //returns 'february'
Explain Buffer data type in Node.js?
Node.js includes an additional data type called Buffer ( not available in browser's JavaScript ). Buffer is mainly used to store binary data, while reading from a file or receiving packets over the network.
Example:
/**
* Buffer Data Type
*/
let b = new Buffer(10000);
let str = "----------";
b.write(str);
console.log( str.length ); // 10
console.log( b.length ); // 10000 What are the core modules of Node.js?
Node.js has a set of core modules that are part of the platform and come with the Node.js installation. These modules can be loaded into the program by using the require function.
Syntax:
const module = require('module_name');
Name Description Assert It is used by Node.js for testing itself. It can be accessed with require('assert'). Buffer It is used to perform operations on raw bytes of data which reside in memory. It can be accessed with require('buffer') Child Process It is used by node.js for managing child processes. It can be accessed with require('child_process'). Cluster This module is used by Node.js to take advantage of multi-core systems, so that it can handle more load. It can be accessed with require('cluster'). Console It is used to write data to console. Node.js has a Console object which contains functions to write data to console. It can be accessed with require('console'). Crypto It is used to support cryptography for encryption and decryption. It can be accessed with require('crypto'). HTTP It includes classes, methods and events to create Node.js http server. URL It includes methods for URL resolution and parsing. Query String It includes methods to deal with query string. Path It includes methods to deal with file paths. File System It includes classes, methods, and events to work with file I/O. Util It includes utility functions useful for programmers. Zlib It is used to compress and decompress data. It can be accessed with require('zlib').
What are the global objects of Node.js?
Node.js Global Objects are the objects that are available in all modules. Global Objects are built-in objects that are part of the JavaScript and can be used directly in the application without importing any particular module.
These objects are modules, functions, strings and object itself as explained below.
1. global:
It is a global namespace. Defining a variable within this namespace makes it globally accessible.
var myvar;
2. process:
It is an inbuilt global object that is an instance of EventEmitter used to get information on current process. It can also be accessed using require() explicitly.
3. console:
It is an inbuilt global object used to print to stdout and stderr.
console.log("Hello World"); // Hello World
4. setTimeout(), clearTimeout(), setInterval(), clearInterval():
The built-in timer functions are globals
function printHello() {
console.log( "Hello, World!");
}
// Now call above function after 2 seconds
var timeoutObj = setTimeout(printHello, 2000);
5. __dirname:
It is a string. It specifies the name of the directory that currently contains the code.
console.log(__dirname);
6. __filename:
It specifies the filename of the code being executed. This is the resolved absolute path of this code file. The value inside a module is the path to that module file.
console.log(__filename);
What is Chrome V8?
Chrome V8 is a JavaScript engine, which means that it executes JavaScript code. Originally, JavaScript was written to be executed by web browsers. Chrome V8, or just V8, can execute JavaScript code either within or outside of a browser, which makes server-side scripting possible.
Like a V8 (eight-cylinder) car engine, Chrome V8 is fast and powerful. V8 translates JavaScript code directly into machine code* so that computers can actually understand it, then it executes the translated, or compiled, code. V8 optimizes JavaScript execution as well.
*Machine code is a language that CPUs can understand. It is purely digital, meaning made up of digits.
Q. How V8 compiles JavaScript code?Compilation is the process of converting human-readable code to machine code. There are two ways to compile the code
- Using an Interpreter: The interpreter scans the code line by line and converts it into byte code.
- Using a Compiler: The Compiler scans the entire document and compiles it into highly optimized byte code.
The V8 engine uses both a compiler and an interpreter and follows just-in-time (JIT) compilation to speed up the execution. JIT compiling works by compiling small portions of code that are just about to be executed. This prevents long compilation time and the code being compiles is only that which is highly likely to run.
What is EventEmitter in Node.js?
If you worked with JavaScript in the browser, you know how much of the interaction of the user is handled through events: mouse clicks, keyboard button presses, reacting to mouse movements, and so on.
On the backend side, Node.js offers us the option to build a similar system using the events module.
This module, in particular, offers the EventEmitter class, which we'll use to handle our events.
You initialize that using
const EventEmitter = require('events'); const eventEmitter = new EventEmitter();
This object exposes, among many others, the on and emit methods.
emitis used to trigger an eventonis used to add a callback function that's going to be executed when the event is triggered
For example, let's create a start event, and as a matter of providing a sample, we react to that by just logging to the console:
eventEmitter.on('start', () => { console.log('started'); });
When we run
eventEmitter.emit('start');
the event handler function is triggered, and we get the console log.
You can pass arguments to the event handler by passing them as additional arguments to emit():
eventEmitter.on('start', number => { console.log(`started ${number}`); }); eventEmitter.emit('start', 23);
Multiple arguments:
eventEmitter.on('start', (start, end) => { console.log(`started from ${start} to ${end}`); }); eventEmitter.emit('start', 1, 100);
The EventEmitter object also exposes several other methods to interact with events, like
once(): add a one-time listenerremoveListener()/off(): remove an event listener from an eventremoveAllListeners(): remove all listeners for an event
You can read more about these methods in the official documentation.
What is EventEmitter in Node.js?
The EventEmitter is a class that facilitates communication/interaction between objects in Node.js. The EventEmitter class can be used to create and handle custom events.
EventEmitter is at the core of Node asynchronous event-driven architecture. Many of Node's built-in modules inherit from EventEmitter including prominent frameworks like Express.js. An emitter object basically has two main features:
- Emitting name events.
- Registering and unregistering listener functions.
Example:
/**
* Callback Events with Parameters
*/
const events = require('events');
const eventEmitter = new events.EventEmitter();
function listener(code, msg) {
console.log(`status ${code} and ${msg}`);
}
eventEmitter.on('status', listener); // Register listener
eventEmitter.emit('status', 200, 'ok');
// Output
status 200 and okQ. How does the EventEmitter works in Node.js?
- Event Emitter emits the data in an event called message
- A Listened is registered on the event message
- when the message event emits some data, the listener will get the data

Building Blocks: https://nodejs.dev/en/api/v19/events/
- .emit() - this method in event emitter is to emit an event in module
- .on() - this method is to listen to data on a registered event in node.js
- .once() - it listen to data on a registered event only once.
- .addListener() - it checks if the listener is registered for an event.
- .removeListener() - it removes the listener for an event.

const { EventEmitter } = require('events');
const emitter = new EventEmitter();
emitter.on('event', (arg1, arg2) => { console.log('Event received:', arg1, arg2);});
emitter.emit('event', 'Hello', 'World!'); ///////////////////////////////////////////////////
const events = require('events');const eventEmitter = new events.EventEmitter();
function listenerOnce() { console.log('listenerOnce fired once');}
eventEmitter.once('listenerOnes', listenerOnce); // Register listenerOnceeventEmitter.emit('listenerOnes');//////////
function listenerOne() { console.log('First Listener Executed');}
function listenerTwo() { console.log('Second Listener Executed');}
eventEmitter.on('listenerOne', listenerOne); // Register for listenerOneeventEmitter.on('listenerOne', listenerTwo); // Register for listenerOne
// When the event "listenerOne" is emitted, both the above callbacks should be invoked.eventEmitter.emit('listenerOnse');


setTimeout():
The setTimeout() function allows users to postpone the execution of code. The setTimeout() method accepts two parameters, one of which is a user-defined function, and the other is a time parameter to delay execution. The time parameter, which is optional to pass, stores the time in milliseconds (1 second = 1000 milliseconds).
The setTimeout() function allows users to postpone the execution of code. The setTimeout() method accepts two parameters, one of which is a user-defined function, and the other is a time parameter to delay execution. The time parameter, which is optional to pass, stores the time in milliseconds (1 second = 1000 milliseconds).
setInterval():
The setInterval method is similar to the setTimeout() function in some ways. It repeats the specified function after a time interval. Alternatively, you can say that a function is executed repeatedly after a certain amount of time specified by the user in this function.
The setInterval method is similar to the setTimeout() function in some ways. It repeats the specified function after a time interval. Alternatively, you can say that a function is executed repeatedly after a certain amount of time specified by the user in this function.
What is the difference between process.nextTick() and setImmediate()?
1. process.nextTick():
The process.nextTick() method adds the callback function to the start of the next event queue. It is to be noted that, at the start of the program process.nextTick() method is called for the first time before the event loop is processed.
2. setImmediate():
The setImmediate() method is used to execute a function right after the current event loop finishes. It is callback function is placed in the check phase of the next event queue.
Example
ssetImmediate(() => {
console.log("1st Immediate");
});
process.nextTick(() => {
console.log("1st Process");
});
// Output
Program Started
1st Process
2nd Process
1st Immediate
2nd ImmediateWhat is a Callback?
A callback function is a simple javascript function that is passed as an argument to another function and is executed when the other function has completed its execution. In layman's terms, a callback is generally used as a parameter to another function. Callbacks in Node.js are so common that you probably used callbacks yourself without understanding that they are called callbacks.
What are the difference between Events and Callbacks?
1. Events:
Node.js events module which emits named events that can cause corresponding functions or callbacks to be called. Functions ( callbacks ) listen or subscribe to a particular event to occur and when that event triggers, all the callbacks subscribed to that event are fired one by one in order to which they were registered.
All objects that emit events are instances of the EventEmitter class. The event can be emitted or listen to an event with the help of EventEmitter
Example:
/**
* Events Module
*/
const event = require('events');
const eventEmitter = new event.EventEmitter();
// add listener function for Sum event
eventEmitter.on('Sum', function(num1, num2) {
console.log('Total: ' + (num1 + num2));
});
// call event
eventEmitter.emit('Sum', 10, 20);
// Output
Total: 30
2. Callbacks:
A callback function is a function passed into another function as an argument, which is then invoked inside the outer function to complete some kind of routine or action.
Example:
/**
* Callbacks
*/
function sum(number) {
console.log('Total: ' + number);
}
function calculator(num1, num2, callback) {
let total = num1 + num2;
callback(total);
}
calculator(10, 20, sum);
// Output
Total: 30
What is callback hell in Node.js?
The callback hell contains complex nested callbacks. Here, every callback takes an argument that is a result of the previous callbacks. In this way, the code structure looks like a pyramid, making it difficult to read and maintain. Also, if there is an error in one function, then all other functions get affected.
An asynchronous function is one where some external activity must complete before a result can be processed; it is "asynchronous" in the sense that there is an unpredictable amount of time before a result becomes available. Such functions require a callback function to handle errors and process the result.
What is typically the first argument passed to a callback handler?
The first parameter of the callback is the error value. If the function hits an error, then they typically call the callback with the first parameter being an Error object.
Explain RESTful Web Services in Node.js?
REST stands for REpresentational State Transfer. REST is web standards based architecture and uses HTTP Protocol. It is an architectural style as well as an approach for communications purposes that is often used in various web services development. A REST Server simply provides access to resources and REST client accesses and modifies the resources using HTTP protocol.
HTTP methods:
https://www.guru99.com/restful-web-services.html
GET− Provides read-only access to a resource.PUT− Updates an existing resource or creates a new resource.DELETE− Removes a resource.POST− Creates a new resource.PATCH− Update/modify a resource
Key Concepts of an API:
- Interface: It provides a way for developers to interact with a service, library, or platform without needing to understand the underlying code or infrastructure.
- Request/Response: APIs typically work through a request/response model. A client (e.g., a web browser or mobile app) sends a request to an API, which processes the request and returns a response.
- Endpoints: An API consists of different endpoints (URLs) that represent specific functionalities or resources. Each endpoint allows for specific actions, such as retrieving data or performing operations.
Four types of web APIs
APIs are broadly accepted and used in web applications. There are four different types of APIs commonly used in web services: public, partner, private and composite. In this context, the API "type" indicates the intended scope of use.
Public APIs. A public API is open and available for use by any outside developer or business. An enterprise that cultivates a business strategy that involves sharing its applications and data with other businesses will develop and offer a public API. These are also called open APIs or external APIs.
Partner APIs. A partner API, only available to specifically selected and authorized outside developers or API consumers, is a means to facilitate business-to-business activities. For example, if a business wants to selectively share its customer data with outside CRM firms, a partner API can connect the internal customer data system with those external parties -- no other API use is permitted.
Partners have clear rights and licenses to access such APIs. For this reason, partner APIs generally incorporate stronger authentication, authorization and security mechanisms. Enterprises also typically do not monetize such APIs directly; partners are paid for their services rather than through API use.
Internal APIs. An internal or private API is intended only for use within the enterprise to connect systems and data within the business. For example, an internal API might connect an organization's payroll and HR systems.
Internal APIs traditionally present weak security and authentication -- or none at all -- because the APIs are intended for internal use, and such security levels are assumed to be in place through other policies. This is changing, however, as greater threat awareness and regulatory compliance demands increasingly influence an organization's API strategy.
Composite APIs. Composite APIs generally combine two or more APIs to craft a sequence of related or interdependent operations. Composite APIs can be beneficial to address complex or tightly related API behaviors and can sometimes improve speed and performance over individual APIs
The terms REST and RESTful API are often used interchangeably, but they have distinct meanings:
REST (Representational State Transfer):
- Definition: REST is an architectural style for designing networked applications. It relies on a stateless, client-server, cacheable communications protocol – the HTTP.
- Principles: REST principles include statelessness, client-server architecture, cacheability, layered system, code on demand (optional), and uniform interface.
RESTful API:
- Definition: A RESTful API is an API that adheres to the principles and constraints of REST. It is designed to take full advantage of the HTTP protocol.
- Characteristics: RESTful APIs are resource-oriented, meaning each resource is identified by a URI. They use standard HTTP methods (GET, POST, PUT, DELETE, etc.) for operations on these resources.
Key Differences:
- REST is the set of architectural principles.
- RESTful API is an implementation of REST principles in an API.
REST API is an architectural style for an API that uses HTTP requests to access and use data, and exchange it securely over the internet. REST API is a way for two computer systems to communicate.
REST APIs work in a similar way that helps you get results for the service you have requested while searching for something on the internet. In 2000, Roy Fielding introduced the concept of REST API specifications, which has later become a dominant practice in modern software engineering.
API is basically a set of rules that developers create on the server-side to enable programs to communicate with each other. And REST determines how the API will look and work and what architectural pattern developers will follow to build it.
Some of the key principles REST APIs follow are:
- Layered system – REST elements cannot see beyond their appointed layer. This results in improved scalability and easier addition of proxies and load balancers.
- Uniform interface – The most important feature of the REST architectural pattern is its emphasis on the uniformity of interfaces between all the components.
- Cacheability – REST servers have to identify their responses as cacheable or not so that disposing of non–cacheable information and caching required information is possible for performance improvement.
- Statelessness – In REST applications, clients maintain the application state, but servers do not manage any client state. The service requests comprise all the information needed for processing.
What is a RESTful API?

RESTful API is an interface that allows two different systems to exchange information over the internet with tight security. RESTful APIs offer a scalable and simple method to construct APIs that are applicable to various programming languages and platforms.
Now RESTful APIs adopt and follow the REST architecture constraints (a set of protocols an API must adhere to), enabling them to be scalable, faster, and support all types of data. An API of this kind access data by using HTTP requests and is the most common type of API used in web development stacks.
Some of the primary components RESTful APIs consist of are:
- Headers – With the help of HTTP headers, RESTful APIs manage information, such as connection types, proxies, and metadata, for request messages as well as their valid responses.
- Data – Data is the body that contains further information on the client-requested resource. When a client determines the content type in the header, the body contains the actual content.
- Method – These APIS manipulate data by using certain HTTP methods like DELETE, POST, or GET to help servers work properly.
- Endpoints – These are URLs that define the data location on the server. Endpoints are basically the resources we try to access via an API.
1. REST vs RESTful API: Architecture
REST app has a layer system and a client-side with uniform UI, whereas a RESTful app has the same architecture with some added features, when it comes to architecture.
The architecture of a REST app has a layer system and a client-side with uniform UI, whereas a RESTful app has the same architecture with some added features.
In addition, a REST server works with a client-server to handle user interactions, and the REST framework manages app performance through an independent system. It identifies any scope of improvement or update in individual tracks.
2. REST vs RESTful API: Consistent UI
As mentioned before, uniform or consistent user interface is one of the key components of REST applications. This is what mostly differentiates REST architectures from other network-based patterns. Such APIs successfully maintain an unchanging interface across different devices.
And in terms of handling data as resources, both RESTful vs REST systems do it with a distinctive and unique namespace.
3. REST vs RESTful API: Caching Capacity
REST APIs suggest data as cacheable/non-cacheable to replace the non-cacheable data, where RESTful apps allow clients to use cacheable data anywhere, anytime.
You can easily improve the performance and functionality of REST systems as the infrastructure and clients are able to store the data. When no one uses the stored data, the system can displace the non-cacheable information.
On the other hand, building a RESTful API enables you to access cacheable data and unchanging states whenever and however you need. It also enables you to follow the latest enterprise web development trends and customize the system as per your requirements.
4. REST vs RESTful API: Stability
REST apps keep up with no client state, and the client deals with each application phase, while RESTful servers just conceal the execution.
Any server request contains all the required information for processing. Assuming that there are any changes in the state of the RESTful APIs, the client answers to the framework for storage capacity and gets the specific contrasting information from REST with system infrastructure. It uses distributed objects to prevent the data from other elements.
In REST frameworks, the client and server trade information about the state and information, whereas RESTful web services do not conceal any data.
What is the difference between req.params and req.query?
The req.params are a part of a path in URL and they're also known as URL variables. for example, if you have the route /books/:id, then the id property will be available as req.params.id. req.params default value is an empty object {}.
A req.query is a part of a URL that assigns values to specified parameters. A query string commonly includes fields added to a base URL by a Web browser or other client application, for example as part of an HTML form. A query is the last part of URL
2. req.params
These are properties attached to the url i.e named route parameters. You prefix the parameter name with a colon(:) when writing your routes.
For instance,
app.get('/giraffe/:number', (req, res) => {
console.log(req.params.number)
})
To send the parameter from the client, just replace its name with the value
GET http://localhost:3000/giraffe/1
3. req.query
req.query is a request object that is populated by request query strings that are found in a URL. These query strings are in key-value form. req.query is mostly used for searching,sorting, filtering, pagination, e.t.c
Say for instance you want to query an API but only want to get data from page 10, this is what you'd generally use.
It written as key=value
GET http://localhost:3000/animals?page=10
To access this in your express server is pretty simple too;
app.get('/animals', ()=>{
console.log(req.query.page) // 10
})
I hope you found this helpful.
Request Body¶
When you need to send data from a client (let's say, a browser) to your API, you send it as a request body.
A request body is data sent by the client to your API. A response body is the data your API sends to the client.
Your API almost always has to send a response body. But clients don't necessarily need to send request bodies all the time.
The req.body property contains key-value pairs of data submitted in the request body. By default, it is undefined and is populated when you use a middleware called body-parsing such as express.urlencoded() or express.json().
Q1) What is Routing in Node.js?
Ans 1) Routing refers to determining how an application responds to a client request to a particular endpoint, which is a URI (or path) and a specific HTTP request method (GET, POST, and so on). In simple terms, Routing allows targeting different routes or different URLs on our page.
Routing refers to how an application's endpoints (URIs) respond to client requests. which is a URI (or path) and a specific HTTP request method (GET, POST, and so on). In
Here we will use the built-in module of node.js i.e. HTTP. So, First load http:
const http = require('http');Now create a server by adding the following lines of code:
http.createServer(function (req, res) {
res.write('Hello World!'); // Write a response
res.end(); // End the response
}).listen(3000, function() {
console.log("server start at port 3000"); // The server object listens on port 3000
});Now add the following lines of code in the above function to perform routing:
const url = req.url;
if(url ==='/about') {
res.write(' Welcome to about us page');
res.end();
} else if(url ==='/contact') {
res.write(' Welcome to contact us page');
res.end();
} else {
res.write('Hello World!');
res.end();
}How many types of streams are present in node.js?
Streams are objects that let you read data from a source or write data to a destination in continuous fashion. There are four types of streams
- Readable − Stream which is used for read operation.
- Writable − Stream which is used for write operation.
- Duplex − Stream which can be used for both read and write operation.
- Transform − A type of duplex stream where the output is computed based on input.
Each type of Stream is an EventEmitter instance and throws several events at different instance of times.
Methods:
- data − This event is fired when there is data is available to read.
- end − This event is fired when there is no more data to read.
- error − This event is fired when there is any error receiving or writing data.
- finish − This event is fired when all the data has been flushed to underlying system.
- IMP ********* https://www.scaler.com/topics/nodejs/streams-in-nodejs/
Streams are objects used to efficiently handle file writes and reads, network communication, or any kind of end-to-end information exchange. Streams are collections of data, just like arrays and strings. The difference is that streams are not available all at once and do not need to be stored in memory. Due to this streams provide a lot of performance and power for node applications to perform a large number of data transfers.
One of the unique features of streams is that instead of reading all the data in memory at once, it reads and processes small pieces of data. In this way, you do not save and process the entire file at once.
Streams can be used to build real-world applications such as video streaming applications like YouTube and Netflix. Both offer a streaming service. With this service, you don't have to download the video or audio feed all at once, but you can watch the video and listen to the audio instantly. This is how the browser receives video and audio as a continuous stream of chunks. If these websites first wait for the entire video and audio to download before streaming, it may take a long time to play the videos.
Streams work on a concept called a buffer. A buffer is a temporary memory used to hold data until the stream is consumed.
Streams in Node.js can provide amazing benefits in terms of memory optimization and efficiency.
Memory efficiency: Streams read chunks of data and process the contents of the file one at a time, rather than holding the entire file in memory at once. This allows data to be exchanged in small chunks, thus significantly reducing memory consumption.
Time efficiency: Streams in Node.js send files in chunks and each chunk is processed separately. So there is no need to wait for the whole data to be sent. As soon as you receive it, you can start processing.
User experience: Thanks to streams, Youtube videos play instantly. YouTube will show the content while it's downloading the rest of the video.
Reduce bandwidth: You can show the initial results of the download to the user and exit if the results are incorrect. Downloading an entire large file only to find out whether it's a wrong file or not is a waste of bandwidth.
Types of Streams in Node.js
There are four fundamental types of streams in Node.js:
Readable: are streams from which data can be read. A readable stream can receive data, but it cannot send data. This is also called piping. Data sent to the read stream is buffered until the consumer starts reading the data. fs.createReadStream() allows us to read the contents of the file. Examples: process.stdin, fs read streams, HTTP responses on the client, HTTP requests on the server, etc.
Writable: are streams to which data can be written. A writable stream can send data, but it cannot receive data. fs.createWriteStream() allows us to write data to a file. Examples: HTTP requests on the client, HTTP responses on the server, fs write streams, process.stout, process.stderr etc.
Duplex: are streams that implement both read and write streams within a single component. It can be used to achieve the read or write mechanism since it does not change the data. Example: TCP socket connection (net.Socket).
Transform: Transform streams are similar to duplex streams, but perform data conversion when writing and reading. Example: read or write data from/to a file.
Node.js Child Processes and Cluster Module: A Guide to High-Performance Applications
https://voskan.host/2023/03/30/node-js-child-processes-and-cluster-module/
What is REPL in context of Node? ☆☆☆
Answer: REPL stands for Read Eval Print Loop and it represents a computer environment like a window console or unix/linux shell where a command is entered and system responds with an output. Node.js or Node comes bundled with a REPL environment. It performs the following desired tasks.
A Read-Eval-Print Loop, or REPL, is a computer environment where user inputs are read and evaluated, and then the results are returned to the user.
- Read - Reads user's input, parse the input into JavaScript data-structure and stores in memory.
- Eval - Takes and evaluates the data structure
- Print - Prints the result
- Loop - Loops the above command until user press ctrl-c twice.
What is Synchronous Code?
When we write a program in JavaScript, it executes line by line. When a line is completely executed, then and then only does the code move forward to execute the next line.
Synchronous code refers to code that runs line by line, where each task must complete before the next one can start. In other words, each operation "blocks" the program's flow until it finishes.
What is Asynchronous Code?
With asynchronous code, multiple tasks can execute at the same time while tasks in the background finish. This is what we call non-blocking code. The execution of other code won't stop while an asynchronous task finishes its work.
Asynchronous code allows a program to perform multiple tasks at once, without having to wait for each task to finish before moving on to the next one.
This is especially useful for time-consuming operations, like fetching data from a server, reading files, or waiting for user input.
Asynchronous code allows tasks to run in the background without stopping the rest of the program. Instead of waiting for a task to finish, the program continues running other tasks and handles the result of the background task once it’s done.
Event-driven: The concept of event-driven is similar to the concept of callback functions in asynchronous programming. In Node.js, callback functions, also known as event handlers, are executed when an event is triggered or completed. Callback functions require fewer resources on the server side and consume less memory. This feature of Node.js makes the application lightweight.
What is a Callback Function in Javascript?
A callback function in javascript is a function that is passed as an argument in another function. Which is then called inside the parent function to complete a routine or an action. To put it more simply, it is a function that will be called(executed) later after its parent function(the function in which it is passed as an argument) is done executing.
higher order functionA higher order function is a function that takes one or more functions as arguments, or returns a function as its result. There are several different types of higher order functions like map and reduce.What is difference between spawn() and fork() methods in Node.js?
1. spawn():
In Node.js, spawn() launches a new process with the available set of commands. This doesn't generate a new V8 instance only a single copy of the node module is active on the processor. It is used when we want the child process to return a large amount of data back to the parent process.
When spawn is called, it creates a streaming interface between the parent and child process. Streaming Interface — one-time buffering of data in a binary format.
Example:
/**
* The spawn() method
*/
const { spawn } = require("child_process");
const child = spawn("dir", ["D:\\empty"], { shell: true });
child.stdout.on("data", (data) => {
console.log(`stdout ${data}`);
});Output
stdout Volume in drive D is Windows
Volume Serial Number is 76EA-3749
stdout
Directory of D:\2. fork():
The fork() is a particular case of spawn() which generates a new V8 engines instance. Through this method, multiple workers run on a single node code base for multiple tasks. It is used to separate computation-intensive tasks from the main event loop.
When fork is called, it creates a communication channel between the parent and child process Communication Channel — messaging
Example:
/**
* The fork() method
*/
const { fork } = require("child_process");
const forked = fork("child.js");
forked.on("message", (msg) => {
console.log("Message from child", msg);
});
forked.send({ message: "fork() method" });/**
* child.js
*/
process.on("message", (msg) => {
console.log("Message from parent:", msg);
});
let counter = 0;
setInterval(() => {
process.send({ counter: counter++ });
}, 1000);Output:
Message from parent: { message: 'fork() method' }
Message from child { counter: 0 }
Message from child { counter: 1 }
Message from child { counter: 2 }
...
...
Message from child { counter: n }What is the purpose of the module .Exports?In Node.js, a module encapsulates all related codes into a single unit of code that can be parsed by moving all relevant functions into a single file. You may export a module with the module and export the function, which lets it be imported into another file with a needed keyword
What is the buffer class in Node.js?
Buffer class stores raw data similar to an array of integers but corresponds to a raw memory allocation outside the V8 heap. Buffer class is used because pure JavaScript is not compatible with binary data
What is the control flow function?
The control flow function is a piece of code that runs in between several asynchronous function calls.
- OPTIONS: describes the supported HTTP methods of resources. Furthermore, it informs these resources options, requirements, and parameters
- GET: employed for receiving information about a resource. In this way, this method can both return already available data or trigger a data-producing process in the server
- HEAD: returns only the metainformation of HTTP headers of a GET method. It means that the body content of an entity isn’t provided
- POST: designed to send a new entity of a resource within the request. Thus, the server subordinates the received entity to the resource
- PUT: sends an enclosed entity of a resource to the server. If the entity already exists, the server updates its data. Otherwise, the server creates a new entity
- DELETE: triggers the deletion of an entity of a resource. The request must inform the target entity
- TRACE: a method with debugging purposes. It returns the entire request to the client. Typically, gateways and proxies tests use this method
- CONNECT: employed for tunneling communications. For example, it is useful to establish connections with SSL-enabled websites
- PATCH: allows the modification of an entity of a resource. So, it can be applied to change only particular portions of an entity data
How to serve static assests from express?
It’s common to have images, CSS and more in a public subfolder, and expose them to the root level:
const express = require('express')
const app = express()
app.use(express.static('public'))
app.listen(3000, () => console.log('Server ready'))
It’s common to have images, CSS and more in a public subfolder, and expose them to the root level:
const express = require('express') const app = express() app.use(express.static('public')) app.listen(3000, () => console.log('Server ready'))
Workflow of Nodejs Server
The workflow of a web server created with Node.js involves all the components discussed in the above section. The entire architectural work has been illustrated in the below diagram.
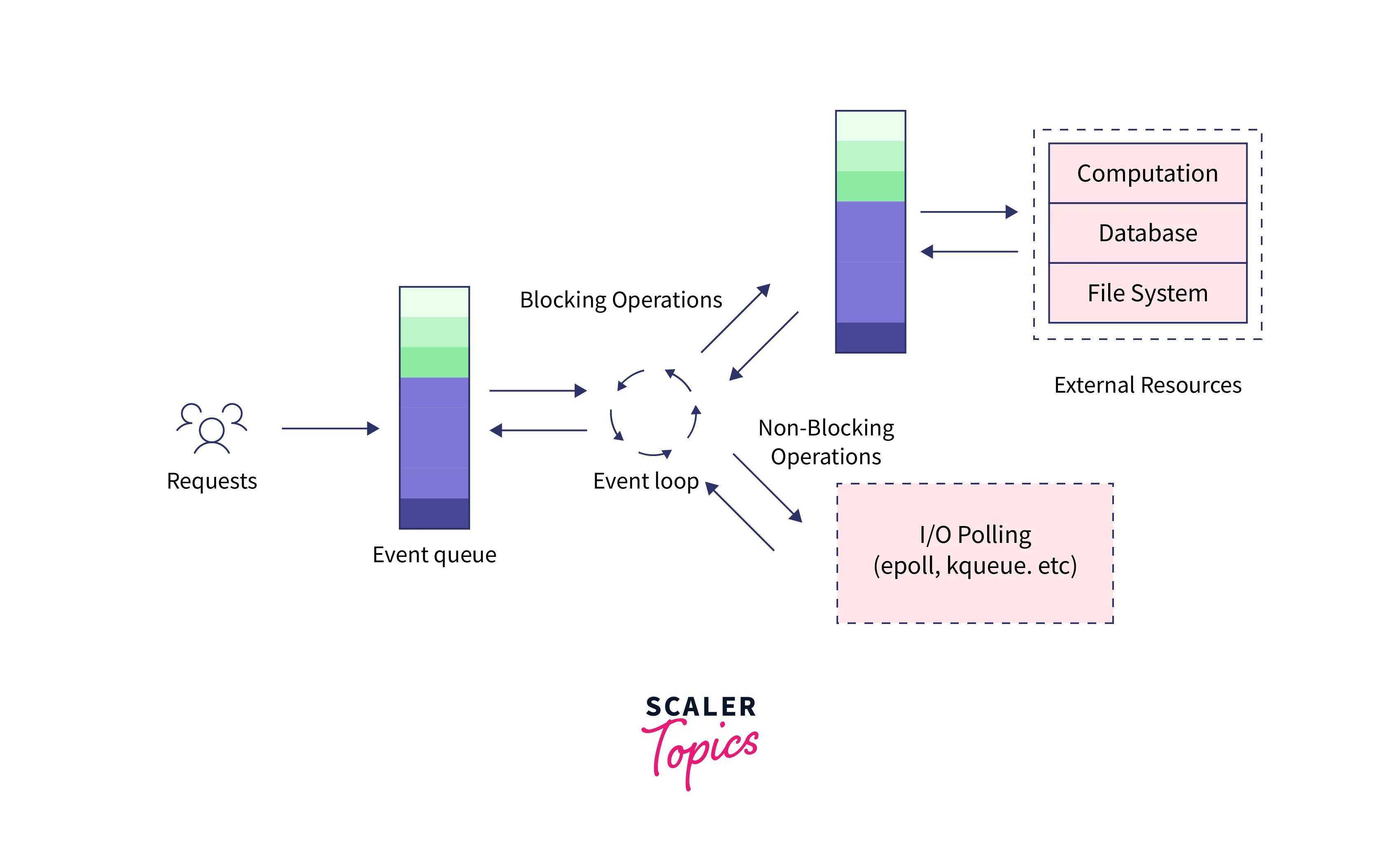
- Clients send requests to the web server. These requests can be either blocking (complex) or non-blocking (simple). The purpose of the requests may be to query for data, delete data or update data.
- The requests are retrieved and added to the event queue.
- The requests are then passed from the event queue to the event loop one by one.
- The simple requests are handled by the main thread, and the response is sent back to the client.
- A complex request is assigned to a thread from the thread pool.
- Clients send requests to the webserver to interact with the web application. Requests can be non-blocking or blocking:
- Querying for data
- Deleting data
- Updating the data
- Node.js retrieves the incoming requests and adds those to the Event Queue
- The requests are then passed one-by-one through the Event Loop. It checks if the requests are simple enough not to require any external resources
- The Event Loop processes simple requests (non-blocking operations), such as I/O Polling, and returns the responses to the corresponding clients
A single thread from the Thread Pool is assigned to a single complex request. This thread is responsible for completing a particular blocking request by accessing external resources, such as computation, database, file system, etc.
Once the task is carried out completely, the response is sent to the Event Loop that sends that response back to the client.
REPL (READ, EVAL, PRINT, LOOP) is a computer environment similar to Shell (Unix/Linux) and command prompt. Node comes with the REPL environment when it is installed. System interacts with the user through outputs of commands/expressions used. It is useful in writing and debugging the codes. The work of REPL can be understood from its full form:
Read : It reads the inputs from users and parses it into JavaScript data structure. It is then stored to memory.
Eval : The parsed JavaScript data structure is evaluated for the results.
Print : The result is printed after the evaluation.
Loop : Loops the input command. To come out of NODE REPL, press ctrl+c twice
Oh boi the event loop. It’s one of those things that every JavaScript developer has to deal with in one way or another, but it can be a bit confusing to understand at first. I’m a visual learner so I thought I’d try to help you by explaining it in a visual way through low-res gifs because it's 2019 and gifs are somehow still pixelated and blurry.
But first, what is the event loop and why should you care?
JavaScript is single-threaded: only one task can run at a time. Usually that’s no big deal, but now imagine you’re running a task which takes 30 seconds.. Ya.. During that task we’re waiting for 30 seconds before anything else can happen (JavaScript runs on the browser’s main thread by default, so the entire UI is stuck) 😬 It’s 2019, no one wants a slow, unresponsive website.
Luckily, the browser gives us some features that the JavaScript engine itself doesn’t provide: a Web API. This includes the DOM API, setTimeout, HTTP requests, and so on. This can help us create some async, non-blocking behavior 🚀
When we invoke a function, it gets added to something called the call stack. The call stack is part of the JS engine, this isn’t browser specific. It’s a stack, meaning that it’s first in, last out (think of a pile of pancakes). When a function returns a value, it gets popped off the stack 👋

The respond function returns a setTimeout function. The setTimeout is provided to us by the Web API: it lets us delay tasks without blocking the main thread. The callback function that we passed to the setTimeout function, the arrow function () => { return 'Hey' } gets added to the Web API. In the meantime, the setTimeout function and the respond function get popped off the stack, they both returned their values!

In the Web API, a timer runs for as long as the second argument we passed to it, 1000ms. The callback doesn’t immediately get added to the call stack, instead it’s passed to something called the queue.

This can be a confusing part: it doesn't mean that the callback function gets added to the callstack(thus returns a value) after 1000ms! It simply gets added to the queue after 1000ms. But it’s a queue, the function has got to wait for its turn!
Now this is the part we’ve all been waiting for… Time for the event loop to do its only task: connecting the queue with the call stack! If the call stack is empty, so if all previously invoked functions have returned their values and have been popped off the stack, the first item in the queue gets added to the call stack. In this case, no other functions were invoked, meaning that the call stack was empty by the time the callback function was the first item in the queue.

The callback is added to the call stack, gets invoked, and returns a value, and gets popped off the stack.

Reading an article is fun, but you'll only get entirely comfortable with this by actually working with it over and over. Try to figure out what gets logged to the console if we run the following:
const foo = () => console.log("First");
const bar = () => setTimeout(() => console.log("Second"), 500);
const baz = () => console.log("Third");
bar();
foo();
baz();
Got it? Let's quickly take a look at what's happening when we're running this code in a browser:
-
The workflow of a web server created with Node.js involves all the components discussed in the above section. The entire architectural work has been illustrated in the below diagram.
- Clients send requests to the web server. These requests can be either blocking (complex) or non-blocking (simple). The purpose of the requests may be to query for data, delete data or update data.
- The requests are retrieved and added to the event queue.
- The requests are then passed from the event queue to the event loop one by one.
- The simple requests are handled by the main thread, and the response is sent back to the client.
- A complex request is assigned to a thread from the thread pool.
- Clients send requests to the webserver to interact with the web application. Requests can be non-blocking or blocking:
- Querying for data
- Deleting data
- Updating the data
- Node.js retrieves the incoming requests and adds those to the Event Queue
- The requests are then passed one-by-one through the Event Loop. It checks if the requests are simple enough not to require any external resources
- The Event Loop processes simple requests (non-blocking operations), such as I/O Polling, and returns the responses to the corresponding clients
A single thread from the Thread Pool is assigned to a single complex request. This thread is responsible for completing a particular blocking request by accessing external resources, such as computation, database, file system, etc.
Once the task is carried out completely, the response is sent to the Event Loop that sends that response back to the client.
REPL (READ, EVAL, PRINT, LOOP) is a computer environment similar to Shell (Unix/Linux) and command prompt. Node comes with the REPL environment when it is installed. System interacts with the user through outputs of commands/expressions used. It is useful in writing and debugging the codes. The work of REPL can be understood from its full form:
Read : It reads the inputs from users and parses it into JavaScript data structure. It is then stored to memory.
Eval : The parsed JavaScript data structure is evaluated for the results.
Print : The result is printed after the evaluation.
Loop : Loops the input command. To come out of NODE REPL, press ctrl+c twice
Oh boi the event loop. It’s one of those things that every JavaScript developer has to deal with in one way or another, but it can be a bit confusing to understand at first. I’m a visual learner so I thought I’d try to help you by explaining it in a visual way through low-res gifs because it's 2019 and gifs are somehow still pixelated and blurry.
But first, what is the event loop and why should you care?
JavaScript is single-threaded: only one task can run at a time. Usually that’s no big deal, but now imagine you’re running a task which takes 30 seconds.. Ya.. During that task we’re waiting for 30 seconds before anything else can happen (JavaScript runs on the browser’s main thread by default, so the entire UI is stuck) 😬 It’s 2019, no one wants a slow, unresponsive website.
Luckily, the browser gives us some features that the JavaScript engine itself doesn’t provide: a Web API. This includes the DOM API, setTimeout, HTTP requests, and so on. This can help us create some async, non-blocking behavior 🚀
When we invoke a function, it gets added to something called the call stack. The call stack is part of the JS engine, this isn’t browser specific. It’s a stack, meaning that it’s first in, last out (think of a pile of pancakes). When a function returns a value, it gets popped off the stack 👋
The respond function returns a setTimeout function. The setTimeout is provided to us by the Web API: it lets us delay tasks without blocking the main thread. The callback function that we passed to the setTimeout function, the arrow function () => { return 'Hey' } gets added to the Web API. In the meantime, the setTimeout function and the respond function get popped off the stack, they both returned their values!
In the Web API, a timer runs for as long as the second argument we passed to it, 1000ms. The callback doesn’t immediately get added to the call stack, instead it’s passed to something called the queue.
This can be a confusing part: it doesn't mean that the callback function gets added to the callstack(thus returns a value) after 1000ms! It simply gets added to the queue after 1000ms. But it’s a queue, the function has got to wait for its turn!
Now this is the part we’ve all been waiting for… Time for the event loop to do its only task: connecting the queue with the call stack! If the call stack is empty, so if all previously invoked functions have returned their values and have been popped off the stack, the first item in the queue gets added to the call stack. In this case, no other functions were invoked, meaning that the call stack was empty by the time the callback function was the first item in the queue.
The callback is added to the call stack, gets invoked, and returns a value, and gets popped off the stack.
Reading an article is fun, but you'll only get entirely comfortable with this by actually working with it over and over. Try to figure out what gets logged to the console if we run the following:
const foo = () => console.log("First");
const bar = () => setTimeout(() => console.log("Second"), 500);
const baz = () => console.log("Third");
bar();
foo();
baz();
Got it? Let's quickly take a look at what's happening when we're running this code in a browser:
Explain the use of next in Node.js?
- The next is a function in the Express router which executes the middleware succeeding the current middleware.
- The next is a function in the Express router which executes the middleware succeeding the current middleware.
Example:
To load the middleware function, call app.use(), specifying the middleware function. For example, the following code loads the myLogger middleware function before the route to the root path (/).
/**
* myLogger
*/
const express = require("express");
const app = express();
const myLogger = function (req, res, next) {
console.log("LOGGED");
next();
};
app.use(myLogger);
app.get("/", (req, res) => {
res.send("Hello World!");
});
app.listen(3000);Why to use Express.js?
Express.js is a Node.js web application framework that provides broad features for building web and mobile applications. It is used to build a single page, multipage, and hybrid web application.
Features of Express.js:
- Fast Server-Side Development: The features of node js help express saving a lot of time.
- Middleware: Middleware is a request handler that has access to the application's request-response cycle.
- Routing: It refers to how an application's endpoint's URLs respond to client requests.
- Templating: It provides templating engines to build dynamic content on the web pages by creating HTML templates on the server.
- Debugging: Express makes it easier as it identifies the exact part where bugs are.
What is the purpose of the module .Exports?
In Node.js, a module encapsulates all related codes into a single unit of code that can be parsed by moving all relevant functions into a single file. You may export a module with the module and export the function, which lets it be imported into another file with a needed keyword.
In real-time applications, fork and spawn are used to handle processes in Node.js. Here’s a brief explanation of each and their use cases:
In Node.js, a module encapsulates all related codes into a single unit of code that can be parsed by moving all relevant functions into a single file. You may export a module with the module and export the function, which lets it be imported into another file with a needed keyword.
In real-time applications, fork and spawn are used to handle processes in Node.js. Here’s a brief explanation of each and their use cases:
fork:
- Use: It’s used to create a new child process that runs a JavaScript file.
- Real-Time Example: In a server application, you might use
fork to run a computationally expensive task (like image processing) in the background without blocking the main server. The parent process and child communicate via messages. - Use Case: Handling heavy background computations, like file uploads, without blocking the main server.
- Use: It’s used to create a new child process that runs a JavaScript file.
- Real-Time Example: In a server application, you might use
forkto run a computationally expensive task (like image processing) in the background without blocking the main server. The parent process and child communicate via messages. - Use Case: Handling heavy background computations, like file uploads, without blocking the main server.
Example:
spawn:
- Use: It’s used to spawn a new process and run an external command or executable. It’s suitable for running system commands or scripts.
- Real-Time Example: Running a system command like
ls or dir to list files in a directory or invoking a script to process data. - Use Case: Running system commands, executing shell scripts, or interacting with other software.
- Use: It’s used to spawn a new process and run an external command or executable. It’s suitable for running system commands or scripts.
- Real-Time Example: Running a system command like
lsordirto list files in a directory or invoking a script to process data. - Use Case: Running system commands, executing shell scripts, or interacting with other software.
Example:
Key Differences:
fork is for creating child processes that run Node.js scripts with inter-process communication (IPC).spawn is used for running external commands or system processes.
forkis for creating child processes that run Node.js scripts with inter-process communication (IPC).spawnis used for running external commands or system processes.
Comments
Post a Comment