vs code practice :
https://www.printfriendly.com/p/g/2HiBsT
https://reimagined-spoon-v6pqx5p944w26gw7.github.dev/
What is Database?
A database is an organized collection of data, so that it can be easily accessed and managed.
The main purpose of the database is to operate a large amount of information by storing, retrieving, and managing data.
What is MongoDB?
MongoDB is a cross-platform document-based database. Categorized as a NoSQL database, MongoDB avoids the conventional table-oriented relational database structure in support of the JSON-like documents with the dynamic schemas, making the data integration in specific kinds of applications quicker and simpler.
It stores the data in the form of the BSON structure-oriented databases. We store these documents in a collection
It's Key Features are:
- Document Oriented and NoSQL database.
- Supports Aggregation
- Uses BSON format
- Sharding (Helps in Horizontal Scalability)
- Supports Ad Hoc Queries
- Schema Less
- Capped Collection
- Indexing (Any field in MongoDB can be indexed)
- MongoDB Replica Set (Provides high availability)
- Supports Multiple Storage Engines
- /////////////////
Scaling horizontally ===> Thousands of minions will do the work together for you.
Scaling vertically ===> One big hulk will do all the work for you.
Horizontal scaling means that you scale by adding more machines into your pool of resources whereas Vertical scaling means that you scale by adding more power (CPU, RAM) to an existing machine.
//////////
What is the difference between MongoDB and MySQL?
|
Explain Indexes in MongoDB?
Why MongoDB is the best NoSQL database?
- MongoDB database are faster than SQL databases due to efficient indexing and storage techniques.
What is MongoDB Replication?
MongoDB replication is the process of creating a copy of the same data set in more than one MongoDB server
- Increase data availability
- Provide a built-in backup solution
A Replica Set requires a minimum of three MongoDB nodes:
- One of the nodes will be considered the primary node that receives all the write operations.
- The others are considered secondary nodes. These secondary nodes will replicate the data from the primary node.
- While the primary node is the only instance that accepts write operations,
- any other node within a replica set can accept read operations.
- These can be configured through a supported MongoDB client.

The Heartbeat process
where the primary node is unreachable and the secondary nodes do not receive a heartbeat from it within the allocated time frame.
Then, MongoDB will automatically assign a secondary server to act as the primary server.
Replica set elections
The elections in replica sets are used to determine which MongoDB node should become the primary node. These elections can occur in the following instances:
- Loss of connectivity to the primary node (detected by heartbeats)
- Initializing a replica set
- Adding a new node to an existing replica set
- Maintenance of a Replica set using stepDown or rs.reconfig methods
In the process of an election, first, one of the nodes will raise a flag requesting an election,
and all the other nodes will vote to elect that node as the primary node. The average time for an election process to complete is 12 seconds,
assuming that replica configuration settings are in their default values. A major factor that may affect the time for an election to complete is the network latency, and it can cause delays in getting your replica set back to operation with the new primary node.
The replica set cannot process any write operations until the election is completed. However, read operations can be served if read queries are configured to be processed on secondary nodes. MongoDB 3.6 supports compatible connectivity drivers to be configured to retry compatible write operations.
MongoDB Replica Set vs MongoDB Cluster
A replica set creates multiple copies of the same data set across the replica set nodes. The basic objective of a replica set is to:
- Increase data availability
- Provide a built-in backup solution
Clusters work differently. The MongoDB cluster distributes the data across multiple nodes using a shard key. This process will break down the data into multiple pieces called shards and then copy each shard to a separate node.
The main purpose of a cluster is to support extremely large data sets and high throughput operations by horizontally scaling the workload.
The major difference between a replica set and a cluster is:
- A replica set copies the data set as a whole.
- A cluster distributes the workload and stores pieces of data (shards) across multiple servers.
What is Sharding in MongoDB?
Sharding is a concept in MongoDB, which splits large data sets into small data sets across multiple MongoDB instances.
Sometimes the data within MongoDB will be so huge, that queries against such big data sets can cause a lot of CPU utilization on the server. To tackle this situation, MongoDB has a concept of Sharding, which is basically the splitting of data sets across multiple MongoDB instances.
The collection which could be large in size is actually split across multiple collections or Shards as they are called. Logically all the shards work as one collection.
Sharding solves the problem with horizontal scaling. With sharding, you add more machines to support data growth and the demands of read and write operations.
Shards − Shards are used to store data. They provide high availability and data consistency. In production environment, each shard is a separate replica set.
Config Servers − Config servers store the cluster's metadata. This data contains a mapping of the cluster's data set to the shards. The query router uses this metadata to target operations to specific shards. In production environment, sharded clusters have exactly 3 config servers.
Query Routers − Query routers are basically mongo instances, interface with client applications and direct operations to the appropriate shard. The query router processes and targets the operations to shards and then returns results to the clients. A sharded cluster can contain more than one query router to divide the client request load. A client sends requests to one query router. Generally, a sharded cluster have many query routers.
////////
Shard Servers: Shard servers are individual nodes within the sharded cluster. Each shard stores a subset of the data and operates as an independent database. MongoDB distributes data across these shard servers to ensure an even distribution.
Config Servers: Config servers store the metadata and configuration information for the sharded cluster, including details about the distribution of data across shards, chunk ranges, and the shard key. Config servers facilitate the coordination of queries and data migrations within the sharded cluster.
Query Routers (mongos): Query routers, also known as “mongos” processes, act as the interface between applications and the sharded cluster. They receive requests, route queries to the appropriate shards, and aggregate results when needed. Mongos processes hide the underlying sharding complexity from the application, making it appear as a single logical database.
Shard Key: The shard key is a field or set of fields chosen to determine how data is distributed across the shards. It’s essential to select an appropriate shard key to ensure even data distribution and efficient querying. A poorly chosen shard key can lead to performance issues.
Chunk: A chunk is a range of data within a shard that is determined by the shard key. Chunks are the units of data migration between shards during rebalancing operations.
Balancer: The balancer is responsible for ensuring an even distribution of data across the shards. As data is added or removed, the balancer migrates chunks of data between shards to maintain data balance and optimal performance.
How to Implement Sharding
Shards are implemented by using clusters which are nothing but a group of MongoDB instances.
The components of a Shard include
- A Shard – This is the basic thing, and this is nothing but a MongoDB instance which holds the subset of the data. In production environments, all shards need to be part of replica sets.
- Config server – This is a mongodb instance which holds metadata about the cluster, basically information about the various mongodb instances which will hold the shard data.
- A Router – This is a mongodb instance which basically is responsible to re-directing the commands send by the client to the right servers.
Step by Step Sharding Cluster Example
Step 1) Create a separate database for the config server.
mkdir /data/configdbStep 2) Start the mongodb instance in configuration mode. Suppose if we have a server named Server D which would be our configuration server, we would need to run the below command to configure the server as a configuration server.
mongod –configdb ServerD: 27019Step 3) Start the mongos instance by specifying the configuration server
mongos –configdb ServerD: 27019Step 4) From the mongo shell connect to the mongo’s instance
mongo –host ServerD –port 27017Step 5) If you have Server A and Server B which needs to be added to the cluster, issue the below commands
sh.addShard("ServerA:27017") sh.addShard("ServerB:27017")Step 6) Enable sharding for the database. So if we need to shard the Employeedb database, issue the below command
sh.enableSharding(Employeedb)Step 7) Enable sharding for the collection. So if we need to shard the Employee collection, issue the below command
Sh.shardCollection("db.Employee" , { "Employeeid" : 1 , "EmployeeName" : 1})
What is the importance of GridFS and Journaling?
GridFS is the MongoDB specification for storing and retrieving large files such as images, audio files, video files, etc. It is kind of a file system to store files but its data is stored within MongoDB collections. GridFS has the capability to store files even greater than its document size limit of 16MB.
GridFS divides a file into chunks and stores each chunk of data in a separate document, each of maximum size 255k.
GridFS by default uses two collections fs.files and fs.chunks to store the file's metadata and the chunks. Each chunk is identified by its unique _id ObjectId field. The fs.files serves as a parent document. The files_id field in the fs.chunks document links the chunk to its parent.
What is Aggregation in MongoDB?
Aggregation is a way of processing a large number of documents in a collection by means of passing them through different stages. The stages make up what is known as a pipeline. The stages in a pipeline can filter, sort, group, reshape and modify documents that pass through the pipeline.
How does the MongoDB aggregation pipeline work?
Here is a diagram to illustrate a typical MongoDB aggregation pipeline.
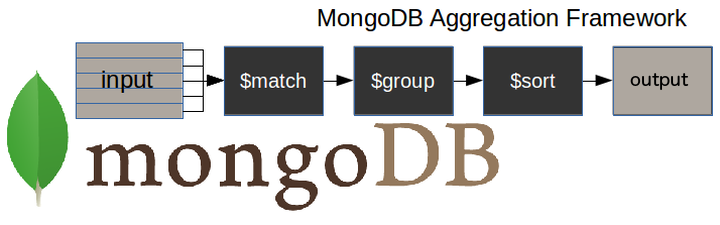
$matchstage – filters those documents we need to work with, those that fit our needs$groupstage – does the aggregation job$sortstage – sorts the resulting documents the way we require (ascending or descending)Pipeline operators:
$match – Filter documents
- $project – Reshape documents
- $group – Summarize documents
- $wind – Expand documents
- $sort – Order documents
- $limit / $skip – Paginate documents
- $redact – restrict documents
- $geoNear – Proximity sort documents
- $let / $map – Bind variables to sub-expressions
- $out – send result to collection
MongoDB aggregate pipeline syntax
This is an example of how to build an aggregation query:
db.collectionName.aggregate(pipeline, options),
- where collectionName – is the name of a collection,
- pipeline – is an array that contains the aggregation stages,
- options – optional parameters for the aggregation
This is an example of the aggregation pipeline syntax:
pipeline = [
{ $match : { … } },
{ $group : { … } },
{ $sort : { … } }
]
Introduction to MapReduce
MapReduce is a programming model and an associated implementation for processing and generating big data sets with a parallel, distributed algorithm on a cluster.
IT is divided into two parts :
1. Mapper: It performs filtering and sorting
2. Reducer: which performs a summary operation (such as counting, aggression )
Map-Reduce in MongoDB
Map-reduce is a data processing pattern for condensing large big data into useful aggregated results. To perform map-reduce operations, MongoDB provides the mapReduce database command.
map is a javascript function that maps a value with a key and emits a key-value pair
reduce is a javascript function that reduces or groups all the documents having the same key
out specifies the location of the map-reduce query result
query specifies the optional selection criteria for selecting documents
sort specifies the optional sort criteria
limit specifies the optional maximum number of documents to be returned
https://www.tutorialspoint.com/mongodb/mongodb_map_reduce.htm
>db.collection.mapReduce(
function() {emit(key,value);}, //map function
function(key,values) {return reduceFunction}, { //reduce function
out: collection,
query: document,
sort: document,
limit: number
}
)MapReduce: Flexible, JavaScript-based framework suitable for complex operations and batch processing but generally slower and less efficient compared to the aggregation framework.
2. What is a document in MongoDB?
A document is a set of key-value pairs stored in a BSON format in MongoDB. BSON is a binary representation of JSON.
3. What is a collection in MongoDB?
A collection in MongoDB is a group of documents that share a similar structure. It is equivalent to a table in a relational database.
10. What is the difference between update and save in MongoDB?
The update method in MongoDB modifies existing documents, while the save method either updates an existing document or inserts a new document if one does not already exist.
11. What is GridFS in MongoDB?
GridFS is a specification for storing and retrieving large files, such as images and videos, in MongoDB.
14. How does MongoDB handle schema changes?
MongoDB allows for flexible schemas, and schema changes can be made without affecting existing data.You can use MongoDB's flexible schema model, which supports differently shaped documents in the same collection, to gradually update your collection's schema. As you update your schema model, the Schema Versioning pattern allows you to track these updates with version numbers.
How do you use transactions?
MongoDB provides two APIs to use transactions. The first is the core API which has similar syntax to relational databases. The second, the callback API, is the recommended approach to using transactions in MongoDB.
What is the role of the mongo shell in MongoDB?
The mongo shell is a command-line interface that allows users to interact with MongoDB and perform administrative tasks
What is the difference between a join and a lookup in MongoDB?
post collection
{
"title" : "my first post",
"author" : "Jim",
"likes" : 5
},
{
"title" : "my second post",
"author" : "Jim",
"likes" : 2
},
{
"title" : "hello world",
"author" : "Joe",
"likes" : 3
}
comment collection
{
"postTitle" : "my first post",
"comment" : "great read",
"likes" : 3
},
{
"postTitle" : "my second post",
"comment" : "good info",
"likes" : 0
},
{
"postTitle" : "my second post",
"comment" : "i liked this post",
"likes" : 12
},
{
"postTitle" : "hello world",
"comment" : "not my favorite",
"likes" : 8
},
{
"postTitle" : "my last post",
"comment" : null,
"likes" : 0
}
Notice how we have two collections posts and comments. The postTitle field in the comments collection corresponds to the title field in the posts collection.
Both comments and posts have likes.
$lookup example: equality match
db.posts.aggregate([
{ $lookup:
{
from: "comments",
localField: "title",
foreignField: "postTitle",
as: "comments"
}
}
])
Notice how $lookup takes a document with the following fields:
- from: the collection we want to join with
- localField: the field we want to join by in the local collection (the collection we are running the query on)
- foreignField: the field we want to join by in the foreign collection (the collection we want to join with)
- as: the name of the output array for the results
This query returns the following..
{
"title" : "my first post",
"author" : "Jim",
"likes" : 5,
"comments" : [
{
"postTitle" : "my first post",
"comment" : "great read",
"likes" : 3
}
]
},
{
"title" : "my second post",
"author" : "Jim",
"likes" : 2,
"comments" : [
{
"postTitle" : "my second post",
"comment" : "good info",
"likes" : 0
},
{
"postTitle" : "my second post",
"comment" : "i liked this post",
"likes" : 12
}
]
},
{
"title" : "hello world",
"author" : "Joe",
"likes" : 3,
"comments" : [
{
"postTitle" : "hello world",
"comment" : "not my favorite",
"likes" : 8
}
]
}MongoDB sort()
In MongoDB, sorting is done by the sort() method. The sort() method consists of two basic building blocks. These building blocks are fields to be sorted and the sort order.
The sorting order in MongoDB is defined by either a one (1) or a minus (-1). Here the positive one represents the ascending order, while the negative one represents the descending order.
How does MongoDB handle data backup and recovery ?
The mongorestore utility restores a binary backup created by mongodump . By default, mongorestore looks for a database backup in the dump/ directory. The mongorestore utility restores data by connecting to a running mongod directly. mongorestore can restore either an entire database backup or a subset of the backup.
FAQs
Q. What is the difference between physical and logical backups in MongoDB?
A: Physical backups involve copying the underlying data files, while logical backups involve exporting the data in a format that can be easily imported.
Q. What backup methods are available in MongoDB?
A: PMongoDB supports several backup methods, including Mongodump, copying underlying files, and using MongoDB Cloud Manager.
Q. What are some best practices for backup and restoration in MongoDB?
A: PBest practices include using a combination of backup methods, testing backups regularly, using multiple backup locations, encrypting backups, and automating backup and restore processes.
Using Mongodump
Mongodump is a MongoDB utility for backing up databases. It exports data in BSON format, enabling simple restoration to a different instance. Mongodump offers numerous options, including authentication and SSL encryption. Users must first connect to the MongoDB instance using the mongo shell or client before running Mongodump with suitable parameters. Mongodump backups are restored using the mongorestore command and are valuable for disaster recovery and migration purposes.
Using MongoDB Cloud Manager
MongoDB Cloud Manager is a cloud-based tool for managing, monitoring, and backing up MongoDB databases on cloud platforms like AWS, Azure, and Google Cloud. It automates tasks such as backup scheduling, recovery, and performance monitoring. Users can store backups securely in AWS S3, Google Cloud Storage, or Azure Blob Storage, with options for scheduling, retention policy, compression, and encryption.
The tool also simplifies backup restoration, with options to restore to the same or different MongoDB instance or a specific point in time. It provides monitoring and alerting features to detect and respond to issues early. MongoDB Cloud Manager reduces data loss risk and offers a comprehensive management solution for cloud-hosted MongoDB databases.
By Copying Underlying Files
Physical backups in MongoDB require stopping the instance and copying the data files (.ns, .bson, and journal) to a secure location. This method ensures an exact backup for disaster recovery but can take longer and need more storage space. To restore, users stop the instance, copy files to the correct location, start the instance, and the database should be restored to the backup's state.
It's important to note that physical backups are not a substitute for other backup methods, like incremental backups or MongoDB's built-in tools. These methods can provide more efficient and reliable backups in certain scenarios, such as with large datasets or when a more granular backup approach is needed. However, physical backups remain a valuable tool for preserving the database's state at a specific point in time and can be essential for disaster recovery.
What Is Mongoose?
Mongoose is a query language to communicate between the server and the database and performs reading, writing, updating and deleting operations of the data.
It is an Object Data Modeling (ODM) library for MongoDB and NodeJS which provides schemas to model application data which therefore cleans up the ambiguity of databases.
It enforces a standard structure to all the documents in a collection using schema.
It also validates the stored data in the documents as well as allow only valid data to be saved in the database.
Overall Mongoose provides all the features to the MongoDB including
query building functions and business logic in the data.
Schema
Mongoose is an ODM (Object database Modelling) library for Node.js that defines objects with a schema mapped to a MongoDB document. A Mongoose Schema defines the structure and property of the document in the MongoDB collection. This Schema is a way to define expected properties and values along with the constraints and indexes.
SchemaTypes
While Mongoose schemas define the overall structure or shape of a document, SchemaTypes define the expected data type for individual fields (String, Number, Boolean, and so on).
Mongoose Schematype is a configuration for the Mongoose model. Before creating a model, we always need to create a Schema. The SchemaType specifies what type of object is required at the given path. If the object doesn’t match, it throws an error. The SchemaType is declared as follows:
const schema = new Schema({
name: { type: String },
age: { type: Number, default: 10 },
});Data Types supported by SchemaType:
- String
- Number
- Date
- Buffer
- Boolean
- Mixed
- ObjectId
- Array
- Decimal128
- Map
- Schema
- options: We can specify different options for a Schema. They are listed as follows:
- required: It takes a boolean value or a function. If specified with boolean, the required validator is added to it.
- default: It takes any data type or a function. It sets a default value for the given path.
- select: It takes a boolean value and specifies the default projection for the queries.
- validate: It accepts a function which validates the data supplied to the path.
- get: Define a custom getter function using Object.defineProperty().
- set: Define a custom setter function using Object.defineProperty().
- alias: It specifies a virtual name for the get and set functions.
- immutable: It takes a boolean type of value, and mongoose prevents changing the immutable path until the parent is specified as isNew=true.
- transform: It takes a function that is used to customize the JSON.stringify() function.
- Indexes: We can define the indexes for the schema options as follows:
- index: It takes a boolean type of value and specifies whether the given path is the index or not.
- unique: It takes a boolean type of value and specifies whether the given path is a unique index or not. If it is true, the index is not required to mention.
- sparse: It takes a boolean type of value and specifies whether the given path is the sparse index or not.
- String: The string type has the following functions:
- lowercase: It takes a boolean type of value and specifies whether to run the toLowerCase() function on the value.
- uppercase: It takes a boolean type of value and specifies whether to run the toUpperCase() function on the value.
- trim: It takes a boolean type of value and specifies whether to run the trim() function on the value.
- match: It has a RegExp which acts as a validator for the value.
- enum: It takes an array and checks if the value is in the array and creates a validator.
- minLength: Specifies the minimum length of the string and creates a validator.
- maxLength: Specifies the maximum length of the string and creates a validator.
- populate: It takes an object and sets the default to populate options.
- Number: The number type has the following functions:
- min: Specifies the minimum value and creates a validator.
- max: Specifies the maximum value and creates a validator.
- enum: It takes an array and checks if the value is in the array and creates a validator.
- populate: It takes an object and sets the default to populate options.
- Date: The date type has the following functions:
- min: Specifies the minimum Date and creates a validator.
- max: Specifies the maximum Date and creates a validator.
- expires: It creates a TTL index with the value expressed in seconds.
- ObjectId: It has the populate function which takes an object and sets the default to populate options.
What is a model?
Models take your schema and apply it to each document in its collection.Models are responsible for all document interactions like creating, reading, updating, and deleting (CRUD).An important note: the first argument passed to the model should be the singular form of your collection name. Mongoose automatically changes this to the plural form, transforms it to lowercase, and uses that for the database collection name.const Blog = mongoose.model('Blog', blog);In this example, Blog translates to the blogs collection.What’s a subdocument
In Mongoose, subdocuments are documents that are nested in other documents. You can spot a subdocument when a schema is nested in another schema.
Note: MongoDB calls subdocuments embedded documents.
const childSchema = new Schema({ name: String, }) const parentSchema = new Schema({ // Single subdocument child: childSchema, // Array of subdocuments children: [childSchema], })In practice, you don’t have to create a separate
childSchemalike the example above. Mongoose helps you create nested schemas when you nest an object in another object.// This code is the same as above const parentSchema = new Schema({ // Single subdocument child: { name: String }, // Array of subdocuments children: [{ name: String }], })
mongoose query
Mongoose models provide several static helper functions for CRUD operations. Each of these functions returns a mongoose Query object.
Mongoose is a tool that allows you to define and work with documents in your MongoDB collections. One of the most important aspects of Mongoose is its Query API, which provides a set of methods for building and executing queries in your MongoDB database. In this article, we will look at some of the common Query API methods available in Mongoose and how they can be used in your application.
Overview Of Mongoose Query API
Mongoose offers a number of static methods on its models that can be used to perform CRUD (create, read, update, delete) operations on the documents in a collection. These methods return a Query object, which can be used to specify additional constraints or to execute the query.
- Model.deleteMany(): Deletes multiple documents from the database that match the specified criteria.
- Model.deleteOne(): Deletes a single document from the database that matches the specified criteria.
- Model.find(): Retrieves one or more documents from the database that match the specified criteria.
- Model.findById(): Retrieves a single document by its unique _id field.
- Model.findByIdAndDelete(): Finds a single document by its _id field and deletes it from the database.
- Model.findByIdAndRemove(): Finds a single document by its _id field and removes it from the database.
- Model.findByIdAndUpdate(): Finds a single document by its _id field and updates it in the database.
- Model.findOne(): Retrieves a single document that matches the specified criteria.
- Model.findOneAndDelete(): Finds a single document that matches the specified criteria and deletes it from the database.
- Model.findOneAndRemove(): Finds a single document that matches the specified criteria and removes it from the database.
- Model.findOneAndReplace(): Finds a single document that matches the specified criteria and replaces it in the database with a new document.
- Model.findOneAndUpdate(): Finds a single document that matches the specified criteria and updates it in the database.
- Model.replaceOne(): Replaces a single document in the database that matches the specified criteria with a new document.
- Model.updateMany(): Updates multiple documents in the database that match the specified criteria.
- Model.updateOne(): Updates a single document in the database that matches the specified criteria
Ref option
Now, you can reference documents in other collections. You can replace a specified path in a document with document(s) from other collection(s), this process is known as population
The ref option is what tells mongoose.js which model to use during population.
Timestamps
Mongoose schemas support a
timestampsoption. If you settimestamps: true, Mongoose will add two properties of typeDateto your schema:createdAt: a date representing when this document was createdupdatedAt: a date representing when this document was last updated
Mongoose will then set
createdAtwhen the document is first inserted, and updateupdatedAtwhenever you update the document usingsave(),updateOne(),updateMany(),findOneAndUpdate(),update(),replaceOne(), orbulkWrite().The MongooseSchemaType.ref() method of the Mongoose API is used to build relationships between two Schema based on Objects Id’s. We can set the reference of a modal using Modal Name, Modal Class, Function that returns Modal Name, and Function that returns Modal Class. We can access the ref() method on an Object of Schema
Mongoose is a MongoDB object modeling and handling for node.js environment. Mongoose Documents represent a one-to-one mapping to documents stored in the database in MongoDB. Each instance of a model is a document. A document can contain any type of data according to the model created.
The following functions are used on the Document of the Mongoose:
- Retrieving: The document is retrieved by different model functions like findOne(), findById().
const doc = MyModel.findById(myid);- Saving: The document is saved by calling the save function. The function is asynchronous and should be awaited.
await doc.save()- Updating using save(): The document can be updated by the save() function as follows:
- The
save()method returns a promise. Ifsave()succeeds, the promise resolves to the document that was saved.]] - MongoDB's update() and save() methods are used to update document into a collection. The update() method updates the values in the existing document while the save() method replaces the existing document with the document passed in save() method.
- Updating using queries: The document can be updated by the queries without calling the save function.
await MyModel.findByIdAndUpdate(myid,{firstname: 'gfg'},function(err, docs){});- Validating: The documents are validated once they are created before saving to MongoDB.
- Documents are casted and validated before they are saved. Mongoose first casts values to the specified type and then validates them. Internally, Mongoose calls the document's
validate()method before saving.
What is Population ??
Population is way of automatically replacing a path in document with actual documents from other collections. E.g. Replace the user id in a document with the data of that user. Mongoose has an awesome method populate to help us. We define refs in ours schema and mongoose uses those refs to look for documents in other collection.
Some points about populate:
- If no document is found to populate, then field will be
null. - In case of array of documents, if documents are not found, it will be an empty array.
- You can chain populate method for populating multiple fields.
- If two populate methods, populate same field, second populate overrides the first one.
- https://dev.to/paras594/how-to-use-populate-in-mongoose-node-js-mo0
Comments
Post a Comment